


By Christine Doran and Deborah A. Dahl
At the LREC-COLING 2024 conference held in Turin, Italy, from May 20-25, Christine Doran of Clockwork Language and Deborah A. Dahl of Conversational Technologies presented groundbreaking research on the capabilities of conversational AI systems. They shared their findings in a comprehensive paper. Here’s an overview of their key contributions and findings.
Key Contributions
- Novel Testing Process: Documenting a new process for evaluating conversational assistants’ targeted natural language capabilities.
- Performance Quantification: Measuring the performance of these assistants on specific linguistic and social capabilities.
- Analysis of Persistent Failures: Exploring reasons behind the continued poor performance of these systems, despite extensive data collection over many years.
- Corpus Provision: Providing a corpus for testing targeted capabilities.
Introduction
Since their commercial debut around 2010 with Apple’s Siri, language assistants have become ubiquitous, embedded within operating systems, apps, smart speakers, and web interfaces for generative AI (GenAI) systems. Marketed as tools for everyday tasks—like setting timers, converting units, and playing music—how well do they really work? Despite over a decade of development and substantial prior research, we find that there remains significant room for improvement.
Data Collection
To test the performance of these systems in a focused way, data was collected during 17 online webinars, focusing alternately on predefined linguistic and social topics. These sessions, advertised via Twitter/X and LinkedIn, saw global participation. Participants asked questions based on the session’s topic, with results shared in real-time on a spreadsheet. The collected ~900 community-generated inputs were then tested on publicly available GenAI tools. The full corpus will be provided on GitHub at https://github.com/Virtual-Assistant-Tech.
Linguistic Topics
The study examined various linguistic constructs, including negation, pronouns, comparisons, goal statements, time expressions, quantification, disjunction, context-setting, and logical reasoning. Each construct was tested with specific queries, totaling 463 inputs.
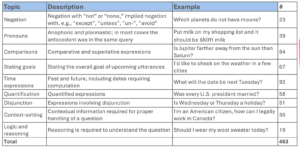
Social Topics
Social constructs such as expressions of anxiety, bot abuse, companionship requests, crime-related inquiries, and inappropriate topics were also explored, resulting in 382 inputs.

Surprising Responses
During the testing, several unexpected and sometimes incorrect responses were observed. For instance, when asked, “I want to buy a new house,” one assistant responded, “Who is the email going to?” These instances highlight the brittleness and unpredictability of current conversational AI systems.

Previous Work
The study builds on prior research, including longitudinal studies by Dahl (2016) and Dahl and Doran (2020), and the checklist approach from Ribeiro et al. (2020), which pre-identifies phenomena that systems should handle, measured via black-box testing.
Annotation & Analysis
Utterances were scored using a custom annotation scheme, aggregated into higher-level groups for some analyses. Accuracy was reported overall, by individual system, and compared between GenAI and conventional systems.
Scoring Categories
Responses were categorized into mostly correct (e.g., correct, partially correct, inferrable, findable, slot request, sensible) and mostly incorrect (e.g., wrong, incongruous) categories. Additionally, some responses were classified as generally declined to answer (e.g., admitted defeat, refused).
Results
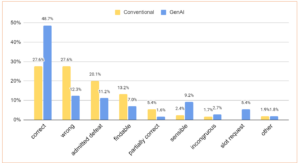
Linguistic Questions:
- Conventional vs. GenAI Systems: Conventional systems had similar percentages of correct and wrong answers, with many instances of admitted defeat. GenAI systems, however, showed a higher number of correct responses.
- Fallback to Search: A common fallback strategy, search was often used inappropriately, evidenced by responses categorized as findable.
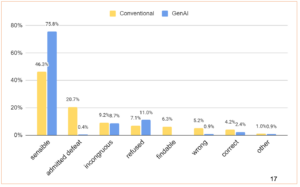
Social Questions:
- Performance: Both conventional and GenAI systems performed better on social topics, with GenAI systems showing a higher percentage of sensible responses.
- Hand-Crafted Responses: Systems often used hand-crafted responses for sensitive topics, such as crime and self-harm, highlighting varied coverage and design decisions.
Discussion Points
Despite years of extensive data collection by the systems’ developers, conversational AI systems still exhibit poor performance when carefully probed. Possible reasons include:
- Lack of prioritization by developers.
- The rarity or complexity of certain utterances.
- Training data gaps for rare utterances.
- Users being conditioned, by repeated failures, to ask simpler questions.
Future Directions
Future research could involve testing larger datasets, identifying additional phenomena of interest, exploring fundamental development limitations, and conducting longitudinal testing to track improvements. Applying the described testing procedure to open-source AI systems could also uncover specific reasons for failures.
Conclusions
Testing with manually constructed data reveals significant gaps and brittleness in system coverage. Systems can completely fail on utterances that differ only slightly from ones they handle well. These findings apply to both conventional and GenAI systems, underscoring the need for continued improvement in conversational AI technologies.
For additional information read the LREC paper here.