



The MOF in a Nutshell
The field of artificial intelligence (AI) is at an inflection point. The rapid rise of generative AI systems and large language models (LLMs) has unlocked unprecedented capabilities in natural language processing, image and video generation, and more. From GPT-4 to Stable Diffusion, these models are capturing the public imagination and driving a new wave of applications and research.
However, amidst the excitement lies a growing unease. Many state-of-the-art AI models remain opaque “black boxes” and their inner workings are shielded from scrutiny. Details about training data, model architectures, and development processes are often scant. This lack of transparency makes it difficult to independently verify claimed capabilities, audit for potential biases and safety issues, and build on the work.
Some model producers have taken steps towards openness by releasing models publicly, but a closer examination reveals concerning patterns. Models purported as “open-source” frequently employ bespoke licenses with ambiguous terms. Documentation is sparse and scattered. Key artifacts like datasets, training code, and benchmarks are absent.
This “open-washing” trend threatens to undermine the very premise of openness – the free sharing of knowledge to enable inspection, replication, and collective advancement. If we are to realize the immense promise of AI while mitigating its risks and pitfalls, we need genuine openness across all stages of the model development lifecycle.
It is in this context that we introduce the Model Openness Framework (MOF). The MOF is a comprehensive framework for objectively evaluating and classifying the completeness and openness of machine learning models. It does so by assessing which components of the model development lifecycle are publicly released and under what licenses.
The framework identifies 17 critical components that constitute a truly complete model release:
 For each component, the MOF stipulates the use of standard open licenses based on the artifact type – open-source licenses for code (e.g. Apache 2.0, MIT), open-data licenses for datasets and model parameters (e.g. CDLA-Permissive, CC-BY), and open-content licenses for documentation and content/unstructured data (e.g. CC-BY).
For each component, the MOF stipulates the use of standard open licenses based on the artifact type – open-source licenses for code (e.g. Apache 2.0, MIT), open-data licenses for datasets and model parameters (e.g. CDLA-Permissive, CC-BY), and open-content licenses for documentation and content/unstructured data (e.g. CC-BY).
Using these building blocks, the MOF defines three progressively broader classes of model openness:
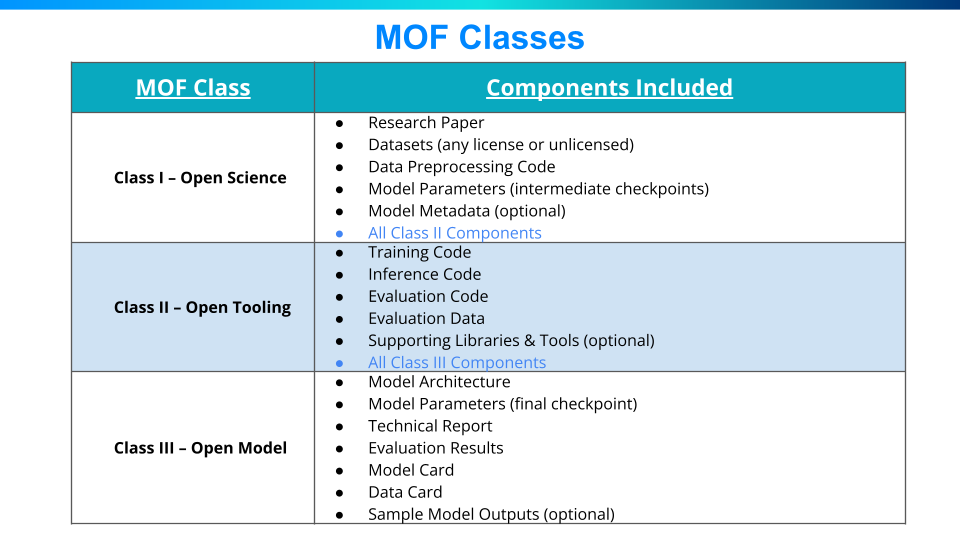
Class III – Open Model: The minimum bar for entry, Class III requires the public release of the core model (architecture, parameters, basic documentation) under open licenses. This allows model consumers to use, analyze, and build on the model, but limits insight into the development process.
Class II – Open Tooling: Building on Class III, this tier includes the full suite of code used to train, evaluate, and run the model, plus key datasets. Releasing these components enables the community to better validate the model and investigate issues. It is a significant step towards reproducibility.
Class I – Open Science: The apex, Class I entails releasing all artifacts following open science principles. In addition to the Class II components, it includes the raw training datasets, a thorough research paper detailing the entire model development process, intermediate checkpoints, log files, and more. This provides unparalleled transparency into the end-to-end development pipeline, empowering collaboration, auditing, and cumulative progress.
By laying out these requirements, the MOF provides both a north star to strive for and a practical roadmap to get there. It turns openness from an abstract ideal to an actionable framework. Model producers have clear guideposts for what and how to release. Model consumers can readily discern the degree of openness and make informed usage decisions.
The Merits of Openness in AI
The power of open science and open source: The MOF reflects a conviction that openness is not just a nice-to-have, but an ethical and scientific imperative in the development of consequential AI systems. It builds on the hard-won lessons and successes of the open science and open source software movements.
Open science has become a clarion call across the research community. From the life sciences to physics and psychology, scholars are embracing practices like code sharing, data sharing, and open access publication for research papers. The benefits have been manifold – greater reproducibility, faster dissemination of results, increased trust, and accelerated discovery through collaboration. The MOF brings this ethos to AI development.
Similarly, open source software has revolutionized the technology industry. The LAMP stack, Linux, and myriad other projects demonstrate the power of community-driven development. Open code has become infrastructure and spawned multi-billion dollar businesses. Bugs are surfaced and fixed faster, new features iterated more rapidly. The MOF recognizes that AI, too, can be democratized and improved through openness.
Indeed, we have already seen the promise of open approaches in AI. The transformative ImageNet dataset was made freely available, catalyzing breakthroughs in computer vision. More recently, initiatives like EleutherAI, The Allen Institute, and RWKV have pioneered the development of open large language models. By making code and models accessible with permissive licensing, they have dramatically expanded participation in AI research and enabled scores of new applications.
The MOF builds on this momentum by providing a systematic framework for open development. It covers not just models, but the entire ML lifecycle, from dataset curation to evaluation and analysis. In doing so, it aims to make open the default, not the exception, in AI.
Just the start: Help us refine the MOF
For the MOF to succeed, it must be a community endeavor. The framework emerged out of discussions with scores of researchers, engineers, ethicists, and legal experts passionate about advancing AI responsibly. But it is only a starting point.
To that end, we invite anyone invested in the future of AI to join the Generative AI Commons, an open and neutral forum dedicated to advancing open science and open source in AI. The community is already hard at work implementing tools to support the MOF, particularly the Model Openness Tool (MOT) at https://isitopen.ai and a badging system to certify openness levels for projects hosted with Github. By joining, you can provide feedback to refine the framework, contribute code, and help advocate for open practices.
The Generative AI Commons is a project of the Linux Foundation’s AI & Data Foundation. As such, it builds on the Linux Foundation’s two decades of experience fostering world-changing open technologies. With a commitment to vendor neutrality, transparency, and inclusion, it provides the necessary infrastructure for sustainable open collaboration in AI.
The road ahead is long but full of promise. With the MOF as a guide and the strength of community, we can chart a course towards AI systems that are open, trustworthy, and beneficial to all. Let us step forward together to make responsible AI a reality.
To learn more and get involved:
- Explore the full Model Openness Framework here
- Join the Generative AI Commons community and mailing list here
- Contribute comments to improve the MOF here
- Advocate for the use of MOF in your organization and network
- Stay tuned for the release of the Model Openness Tool here
The future is open. Let’s build it together.