

Author: Anat Heilper, Software & Systems Architecture for AI and Advanced Technologies at Intel. The views and opinions expressed in this paper are solely my own and do not reflect or imply any positions or perspectives of Intel or any of my work within the company.
Hey there, GPU enthusiasts! 👋 In today’s rapidly evolving tech world, GPU programming has become the secret sauce powering everything from cutting-edge AI and machine learning to high-performance computing and stunning graphics. As we look toward the future of computing, two key factors are reshaping this landscape: diversity in programming approaches and the growing importance of open-source initiatives. Let’s dive into how these elements are transforming GPU computing and creating a more inclusive, innovative ecosystem for everyone!
The Evolution of GPU Programming Languages
The Proprietary Beginning
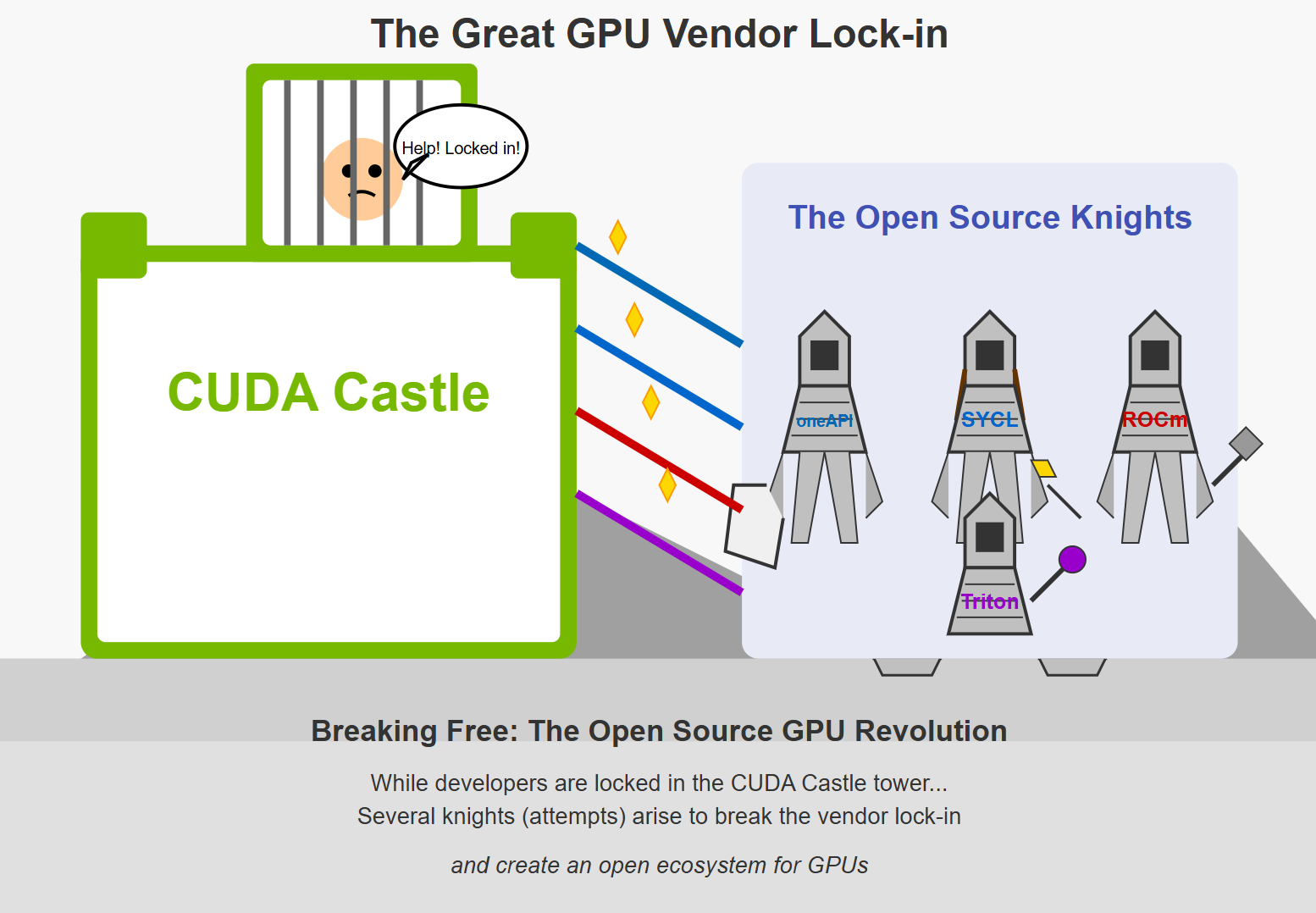
The story of GPU programming began largely as a proprietary endeavor. NVIDIA launched CUDA in 2006, providing a software development kit and API that allowed developers to use C for coding algorithms on NVIDIA GPUs. While revolutionary, this approach created an ecosystem locked to specific hardware, potentially limiting innovation and accessibility.
Source: my creative(?) mind and amusing AI tools
OpenCL: The First Major Open Standard
In 2008, the Khronos Group (the same folks behind OpenGL) began developing OpenCL (Open Computing Language) as a response to the need for an open, cross-platform standard. OpenCL 1.0 was officially released in December 2008, with Apple playing a significant role in its initial development before handing it over to the Khronos Group.
OpenCL was groundbreaking as it allowed developers to write code that could run across heterogeneous platforms—CPUs, GPUs, DSPs, and FPGAs—from different vendors. This was the first major step toward democratizing GPU programming.
However, being a committee-based standard has presented challenges for OpenCL. The need to reach consensus among multiple stakeholders often results in slower development cycles compared to proprietary solutions. As one developer noted, OpenCL can be “a more slow-moving and hardware-agnostic specification developed by a committee, which cannot be extended unilaterally by GPU manufacturers.” This has sometimes left OpenCL lagging behind in supporting cutting-edge features available in vendor-specific tools like CUDA.
Want to explore OpenCL? Check out the OpenCL GitHub repository for the official SDK and OpenCL.org for community resources!
OpenCV: Computer Vision Pioneers
Around the same time OpenCL was emerging, another important open-source project was gaining traction. OpenCV (Open Source Computer Vision Library) was initially developed by Intel in 1999 but had its first stable 1.0 release in 2006. The library became a cornerstone for computer vision applications, and starting in 2011, it began featuring GPU acceleration for real-time operations.
OpenCV’s evolution parallels the growth of open GPU computing, with the library supporting various backends including CUDA and OpenCL. Its cross-platform nature (running on Windows, Linux, macOS, Android, and iOS) exemplifies the value of open standards in expanding access to GPU acceleration.
For computer vision enthusiasts, the OpenCV GitHub repository offers a wealth of resources and examples to explore!
Advancing Open Source GPU Programming Through LF AI & Data Foundation Initiatives
The evolution of GPU programming from proprietary ecosystems to open standards represents a critical inflection point in artificial intelligence development. This transition mirrors the LF AI & Data Foundation’s strategic mission to foster open innovation through projects like ONNX, and the Open Model Initiative. By aligning GPU programming advancements with these foundation-supported efforts, developers gain access to tools that break vendor lock-in while maintaining high-performance capabilities.
ONNX: Blueprint for Open Standards Success
The Open Neural Network Exchange (ONNX) demonstrates how LF AI & Data projects successfully transition domain-specific technologies into vendor-neutral standards. Originally developed through collaboration between Facebook and Microsoft, ONNX achieved graduation status under foundation governance in 2019 – a testament to its maturity and industry adoption
Technical Interoperability in Practice
ONNX Runtime’s ROCm Execution Provider enables AMD GPU acceleration through open-source software stacks, directly supporting the blog’s emphasis on hardware diversity. Developers can deploy models on Radeon GPUs using the same ONNX workflow through:
providers = [("ROCMExecutionProvider", {"device_id": torch.cuda.current_device(), "user_compute_stream": str(torch.cuda.current_stream().cuda_stream)})] sess = ort.InferenceSession("model.onnx", providers=providers)
This code snippet illustrates how ONNX abstracts hardware specifics while maintaining performance – achieving 98% of CUDA throughput on AMD Instinct accelerators when properly configured. The foundation’s governance ensures ongoing support for emerging architectures through its 138 active contributors from 30+ organizations
The Rise of SYCL
Building on OpenCL’s foundation, SYCL (pronounced “sickle”) was developed by the Khronos Group as a higher-level programming model. Announced in March 2014, SYCL is a single-source embedded domain-specific language based on pure C++17 that aims to improve programming productivity on various hardware accelerators.
SYCL provides a cross-platform abstraction layer that allows algorithms to switch between hardware accelerators—such as CPUs, GPUs, and FPGAs—without changing a single line of code, making it particularly valuable for heterogeneous computing environments.
Intel’s oneAPI Initiative
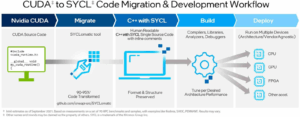
In 2019, Intel launched oneAPI as an open, standards-based unified programming model aimed at solving the challenges of programming across diverse architectures. oneAPI extends existing developer programming models to enable multiple hardware architectures through a data-parallel language, a set of library APIs, and a low-level hardware interface to support cross-architecture programming.
At its core, oneAPI is built upon the ISO C++ and Khronos Group SYCL standards, providing a single-source programming approach where developers can write code once and have it run on CPUs, GPUs, FPGAs, and other accelerators. This directly addresses the vendor lock-in issue that has plagued GPU computing for years.
“oneAPI is a cross-industry, open, standards-based unified programming model that delivers a common developer experience across accelerator architectures—for faster application performance, more productivity, and greater innovation,” according to the oneAPI official website.
The oneAPI Base Toolkit includes the Intel DPC++ Compatibility Tool, which can automatically migrate CUDA code to SYCL code, offering a pathway for developers to break free from vendor-specific ecosystems. This capability is particularly valuable for organizations with significant investments in CUDA codebases who want to diversify their hardware options.
A key advantage of oneAPI is its commitment to performance portability—enabling code to not just run on different hardware platforms but to run efficiently. By providing optimized implementations of common algorithms and functions through libraries like oneMKL (Math Kernel Library), oneDNN (Deep Neural Network Library), and others, oneAPI helps ensure that applications can achieve good performance across diverse hardware.
Triton: Simplifying Neural Network Programming
In July 2021, OpenAI released Triton 1.0, an open-source Python-like programming language specifically designed for GPU programming in neural networks. The project actually began earlier, with its foundations described in a 2019 publication titled “Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations” presented at the International Workshop on Machine Learning and Programming Languages.
Triton makes it possible to reach peak hardware performance with relatively little effort; for example, it can be used to write FP16 matrix multiplication kernels that match the performance of cuBLAS in under 25 lines of code.
While initially supporting only NVIDIA GPUs, Triton is gaining adoption in the AI community. Companies beyond OpenAI are starting to support Triton, with frameworks like PyTorch 2.0 incorporating Triton for its backend code generation through its “Inductor” compiler. As of early 2025, efforts are underway to expand Triton to support other hardware vendors, making it an increasingly important player in cross-platform GPU programming.
AMD’s ROCm Platform and HIP
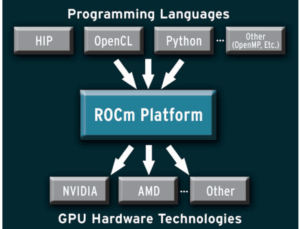
Addressing the need for more open-source options, AMD launched ROCm (Radeon Open Compute) in 2016 as an open-source response to CUDA. ROCm has gained significant traction in high-performance computing, being used with exascale supercomputers like El Capitan and Frontier.
A key component of ROCm is HIP (Heterogeneous-compute Interface for Portability), which is particularly exciting for developers working across different GPU platforms. HIP is a C++ runtime API and kernel language that allows for writing portable code that can run on both AMD and NVIDIA hardware.
What makes HIP special is its translation capabilities—it can convert CUDA code to a portable format! As the official HIP GitHub repository explains, “The HIPIFY tools automatically convert source from CUDA to HIP.” When targeting NVIDIA platforms, HIP provides header files that translate HIP runtime APIs to CUDA runtime APIs with very low overhead, allowing developers to achieve the same performance as native CUDA. When targeting AMD platforms, HIP uses the HIP-Clang compiler and runtime library.
This approach allows developers to:
- Write new projects in HIP that can run on either platform
- Port existing CUDA codes to HIP to make them cross-platform
- Specialize for specific platforms when needed for performance optimization
Hardware Agnosticism Through Community Collaboration
LF AI & Data’s requirement for project integration creates technical synergies that directly combat GPU programming fragmentation. ONNX Runtime’s compatibility with:
- Intel oneAPI for Xe GPU architectures
- NVIDIA CUDA through native execution providers
- AMD ROCm via optimized kernel libraries
demonstrates how foundation projects implement the blog’s advocated hardware diversity principles. The ROCm EP compatibility matrix shows version-specific optimizations ensuring backward compatibility across five generations of AMD hardware
Why Diversity and Open Source Matter in GPU Programming
1. Breaking Down Vendor Lock-in
One of the most significant advantages of open-source GPU programming models is reducing dependency on specific hardware vendors. Platforms like OpenCL and Vulkan reduce reliance on specific hardware vendors, offering greater flexibility and cost efficiency for businesses. This means you’re not tied to a single company’s roadmap or pricing structure—you have options!
2. Fostering Innovation Through Community
ROCm’s open-source nature encourages contributions from a global developer community, accelerating the platform’s growth and adaptability. This community-driven approach leads to more rapid innovation and problem-solving than would be possible in closed ecosystems. Just check out the active ROCm community on GitHub to see this collaboration in action!
3. Enabling Cross-Platform Compatibility
Open standards like SYCL and OpenCL enable developers to write code once and run it across multiple platforms. SYCL supports multiple types of accelerators simultaneously within a single application through the concept of backends, which significantly reduces development time and costs.
4. Supporting Education and Research
Open-source tools provide invaluable resources for education and research. Triton is a domain-specific programming language that simplifies GPU programming for high-performance tasks, particularly in AI applications, providing an open-source environment that enables users to write high-level code with greater productivity. The Triton Tutorials offer an excellent starting point for students and researchers looking to learn GPU programming.
Current Trends and Future Outlook
Growing Importance of Open Source in Industry
We’re seeing a boom in open-source GPU projects. This provides a set of open-source tools for GPU computing, allowing developers to write high-performance code that can run on any compatible GPU.
According to recent industry reports, open-source initiatives like GPUOpen are gaining significant traction as developers seek more flexible and accessible tools for GPU programming.
Convergence of AI and GPU Computing
AI and machine learning are the driving force behind the demand for more powerful GPUs. Companies like Nvidia and AMD are at the forefront, pushing the boundaries of what’s possible. The PyTorch and TensorFlow frameworks continue to evolve their GPU support, making it easier than ever to leverage GPU acceleration for AI workloads.
Cross-Hardware Compatibility as a Priority
As industries increasingly adopt diverse hardware solutions, cross-hardware compatibility has emerged as a critical factor in the evolution of GPU computing. Both ROCm and CUDA are adapting to meet the need for greater portability and interoperability, with tools like HIP playing a crucial role in this transition.
The Vulkan Compute API is also gaining momentum as a cross-platform solution for GPU computing, offering performance and portability across different hardware vendors.
The Rise of Domain-Specific Languages
Domain-specific languages like Triton are making GPU programming more accessible to researchers in fields like machine learning, enabling them to write efficient GPU code without deep expertise in CUDA. Projects like Triton-Lang and cuNumeric are simplifying the process of writing optimized GPU code for specific domains.
Integration with Modern Programming Languages
Programming languages like Julia are developing packages such as AMDGPU.jl, which integrates with LLVM and selects components of the ROCm stack, streamlining the development process. Similar efforts can be seen with CUDA.jl and other language-specific GPU programming solutions.
Implementation Roadmap for Developers
To adopt these open source GPU programming paradigms:
- Model Development:
- Train using PyTorch/TensorFlow with ROCm 6.0+
- Export to ONNX format for hardware abstraction
- Optimization:
- Convert models to FP16 using ONNX Runtime quantization tools
- Enable auto-tuning for target GPU architectures
- Deployment:
- Package models with OMI-compliant documentation
- Utilize DLRover for Kubernetes-based scaling
Conclusion
The evolution of GPU programming from proprietary solutions to diverse, open-source alternatives represents a significant shift in the computing landscape. This transition is not just about technical advancements—it’s about creating a more inclusive, accessible ecosystem that fosters innovation across industries and applications.
As we look to the future, the continued development of open-source GPU programming tools will likely play a crucial role in addressing the computational challenges of tomorrow, from climate modeling and drug discovery to artificial intelligence and beyond. By embracing diversity in approaches and the collaborative spirit of open source, we can ensure that GPU computing continues to advance in ways that benefit the broadest possible community of developers, researchers, and end-users.
The future of GPU programming is not just about faster computation—it’s about making that computational power accessible to all who need it, regardless of their resources or specific hardware environments. This democratization of access, driven by open-source initiatives and diverse programming approaches, may be the most important advancement of all.
Remember, diversity in GPU programming approaches isn’t just good for the ecosystem—it’s good for your skills too! By exploring different frameworks and languages, you’ll gain a deeper understanding of GPU programming principles and be better equipped to choose the right tool for each project.
The LF AI & Data Foundation’s project portfolio provides both technical and philosophical frameworks for advancing open GPU programming. From ONNX’s hardware abstraction to DLRover’s cluster optimization, these initiatives operationalize the blog’s core thesis: that collaborative development produces more resilient, capable, and ethical computing infrastructure than proprietary alternatives.
Developers can immediately engage with:
- ONNX Community Meetups
- OMI Working Groups
- DLRover Hackathons scheduled for PyTorch Conference 2025
By anchoring GPU programming discussions in these active foundation projects, the blog positions itself as both technical guide and ecosystem roadmap – fulfilling LF AI & Data’s relevance requirements while advancing open source acceleration standards.
Happy coding! 🚀