

This post initially published on open.Intel and was re-posted with permission
Generative AI (GenAI) is revolutionizing how applications are built and deployed, from intelligent chatbots to code generation. Yet, organizations often struggle to bridge the gap between off-the-shelf AI capabilities and real-world enterprise requirements. Two key challenges stand out: the need for standardization in how we build GenAI solutions, and the need for customization to fit domain-specific data and use cases. In this blog post, we explore these challenges and how the Open Platform for Enterprise AI (OPEA) blueprints and the IBM Data Prep Kit (DPK) provide a path forward. We’ll use a concrete example – deploying and customizing a ChatQnA application using a retrieval augmented generation (RAG) architecture – to illustrate how OPEA and DPK work together in practice.
Why Standardization and Customization Matter
Enterprises developing generative AI (GenAI) applications face a fundamental challenge: how to balance the need for standardization with the demand for deep customization. Achieving the right mix is critical for building scalable, efficient, and business-relevant AI solutions. For organizations building GenAI applications, a lack of standardization often leads to:
- Inconsistent solutions: Diverse models and fragmented tools make it difficult to maintain quality and reliability across business units.
- Inefficient scaling: Without standardized pipelines and workflows, replicating successful AI solutions across teams or regions becomes slow and costly.
- Increased operational overhead: Managing a patchwork of custom tools and models strains IT resources and complicates support and maintenance.
The Case for Customization
While standardization brings consistency, it can’t address every business need. Enterprises operate in complex, dynamic environments, often spanning multiple industries, regions, and regulatory landscapes. Generic, off-the-shelf AI models typically fail to deliver:
- Industry or domain-specific accuracy: AI models trained on generic datasets may underperform when faced with specialized terminology, workflows, or compliance requirements unique to a sector like healthcare, finance, or automotive.
- Alignment with business goals: Customization allows organizations to fine-tune AI models to support specific objectives—whether it’s optimizing supply chains, personalizing customer experiences, or improving product quality.
- Data privacy and compliance: Custom AI solutions can be built and trained on proprietary data, ensuring sensitive information stays in-house and regulatory standards are met.
Customization empowers enterprises to unlock unique insights, drive innovation, and gain a competitive advantage by addressing challenges that generic solutions cannot.
Given the need for both standardization and customization, how do we find a balance?
OPEA Blueprints: Modular AI Deployment
OPEA, an open source project under LF AI & Data, provides standardized blueprints for building enterprise-grade GenAI applications, including RAG architectures that also enable customization.
Key features include:
- Modular microservices: Easily scalable and interchangeable components.
- End-to-end workflows: Reference architectures for common GenAI tasks, like chatbots and document summarization.
- Open and vendor-neutral: Integrates diverse open source technologies and avoids vendor lock-in.
- Cloud and hardware flexibility: Supports CPUs, GPUs, and AI accelerators across diverse environments.
Example: The OPEA ChatQnA blueprint offers a standardized RAG-based chatbot system, comprising embedding, retrieval, reranking, and inference services, orchestrated via APIs for rapid deployment.
IBM Data Prep Kit: Streamlined Data Preparation
Preparing high-quality data for AI and large language model (LLM) applications is a complex, resource-intensive process. IBM’s Data Prep Kit (DPK) tackles this challenge by providing an open source, scalable toolkit that streamlines every stage of data preprocessing—from ingestion and cleaning to annotation and embedding generation—across diverse data types and enterprise-scale workloads.
DPK enables:
- Comprehensive preprocessing: Modules for ingestion, cleaning, chunking, annotation, and embedding generation.
- Scalable execution: Supports distributed processing frameworks like Apache Spark and Ray.
- Community-driven extensibility: Open source modules easily adapted to specific use cases.
Example: Using DPK, organizations can quickly process raw documents (PDFs, HTML), convert them into structured embeddings, and populate a vector database, enabling AI systems to generate accurate, domain-specific responses.
Deploying ChatQnA with OPEA and DPK
To understand how standardized frameworks and tailored data pipelines converge in real-world AI deployments, let’s examine the ChatQnA RAG workflow. This end-to-end example demonstrates how OPEA’s modular architecture and DPK’s data processing capabilities work in tandem, from ingesting raw documents to generating context-aware responses.
In this example, we show how enterprises can balance consistency and flexibility using prebuilt components for rapid deployment while customizing critical stages like embedding generation and LLM integration. In this example, DPK ingests documents on a Milvus vector database and OPEA provides a blueprint that you can either use out of the box or adapt to your own infrastructure through reusable components, such as data preparation, vector stores, or retrievers. If your use case requires it, you can go one step further and build your own components from scratch.
Below, we break down each phase of the workflow, highlighting the interplay between standardized microservices and domain-specific data handling.
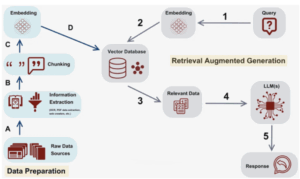
In the ChatQnA RAG workflow, data flows from ingestion on the left to answer generation on the right. On the left, raw data sources (A) go through extraction (B) and chunking (C) transforms the data during data preparation. The chunks are then embedded (D) into vector representations and stored in a vector database. On the right, a user query is also converted to an embedding (1) which is used to retrieve relevant data (2,3) from the vector store. The retrieved context is fed into an LLM (4) to generate a final response (5). This RAG approach ensures the LLM’s answer is grounded in the content from the knowledge base.
Deploying a ChatQnA chatbot illustrates the synergy between OPEA and DPK:
- Data Preparation (DPK):
- Ingests raw documents and performs OCR/extraction
- Cleans and chunks content into manageable pieces
- Generates embeddings and populates a vector database
- AI Application Deployment (OPEA):
- Deploys modular microservices (embedding, retrieval, reranking, inference)
- Easily swaps or scales components (e.g., larger LLM models or different databases)
- End-User Interaction:
- User queries trigger embedding and retrieval of relevant context
- Context-enriched responses generated by an LLM
This standardized, yet customizable, pipeline accelerates development, enhances scalability, and ensures relevant AI-driven interactions.
Get Started and Contribute
We encourage you to try it out for yourself by exploring and contributing to these open source initiatives:
- Streamlining Enterprise AI RAG Pipelines with OPEA and IBM DataPrepKit Workshop
- Open Platform for Enterprise AI (OPEA) ChatQnA Blueprint with Milvus as a Vector Database Deployment (DOCKER) Notebook
Join us in building the future of enterprise-grade GenAI solutions!
About the Authors
Ezequiel (Eze) Lanza
Open Source AI Evangelist at Intel (TAC Chair for LF AI and Data)
Hi, I’m Ezequiel (Eze) Lanza, and I’m passionate about helping people explore artificial intelligence. As a regular AI conference presenter, I take pride in creating impactful use cases, tutorials, and guides to assist developers in adopting open source AI tools. With a solid foundation in engineering and a decade of experience assisting customers and developers in the software realm, I bring a wealth of practical knowledge to the table. Currently, I’m writing my thesis as I pursue a master’s in data science from Universidad Austral in Argentina (Yeah, it was AI before ChatGPT:).
Sujee Maniyam
AI Engineer, Developer Advocate at Node51 (Consulting for IBM / The AI Alliance)
Sujee Maniyam is an expert in GenAI, machine learning, deep learning, big data, distributed systems, and cloud technologies. He is passionate about developer education and fostering community engagement. Sujee has led numerous training sessions, hackathons, and workshops. He is also an author, open source contributor, and frequent speaker at conferences and meetups.
Murilo Gustineli
Senior AI Software Solutions Engineer at Intel
I’m a senior AI software solutions engineer at Intel, currently pursuing a master’s in computer science at Georgia Tech focusing on machine learning. My work involves creating synthetic datasets, fine-tuning large language models, and training multi-modal models using Intel’s Gaudi accelerators as part of the Development Enablement team. I’m particularly interested in deep learning, information retrieval, and biodiversity research, aiming to improve species identification and support conservation efforts.