


Authors: Raghavan Muthuregunathan, Jigisha Mavani
The LF AI & Data Generative AI Commons is dedicated to fostering the democratization, advancement and adoption of efficient, secure, reliable, and ethical Generative AI open source innovations through neutral governance, open and transparent collaboration and education. Large Language Models (LLMs) have revolutionized the field of natural language processing, enabling users to interact with AI systems through direct prompting. However, the majority of LLMs are trained on English-centric datasets, leading to disparities in performance when processing non-English prompts. To realize our vision of democratizing artificial intelligence, LLM applications must reach the last mile user, especially outside the anglosphere. This article explores the challenges non-English users face and presents a prompt engineering solution in the form of Translation Augmented Generation. This article was presented in the Open Source Summit North America 2024.
The Dominance of English in LLM training data
The training data used by most LLMs, such as the Common Crawl dataset used by the GPT series, is heavily skewed towards English content. [1] Wikipedia reports that 46% of the dataset is in English, with other languages like German, Russian, Japanese, French, Spanish, and Chinese each accounting for less than 6%. This disparity in training data results in a poorer understanding of non-English semantics and collective knowledge by the LLMs. This impacts the response quality of prompts from low-resource languages. Low-resource languages [7] are defined as languages that have less data available for AI training.
Challenges with using Existing Models and Non-English Prompts
Text-to-Text LLMs
Although text-to-text LLMs are continuously evolving, users have observed LLMs exhibiting suboptimal performance when prompted with instructions in languages other than English. They may fail to
- follow instructions accurately,
- create language mismatch between question and answer
- produce outputs of lower quality compared to their English counterparts.
| Problem | Language | LLM |
| Does not follow instruction accurately
English Prompt: Prompt: Write 3 paragraphs 4 lines each about Proton, electron and neutron in that order |
Tamil (spoken in India, Singapore, Srilanka, Malaysia)
Prompt: புரோட்டான், எலக்ட்ரான் மற்றும் நியூட்ரான் பற்றி 3 பத்திகள் 4 வரிகளை அந்த வரிசையில் எழுதவும் Response is 3 bullet points |
Link
GPT 3.5 |
| Language mismatch
English prompt: write a story about someone being helpful in 4 paragraphs |
Somalian: (spoken in Somalia and Ethiopia)
Prompt: qor sheeko ku saabsan qof ku caawinaya 4 cutub The response is in English, while the input is in Somalian. |
Link
GPT 3.5 |
| Lower quality inaccurate response
English prompt: How long does it take for light to travel from sun to earth ? |
Bengali (spoken in Bangladesh and India)
Prompt: সূর্য থেকে পৃথিবীতে আলো আসতে কত সময় লাগে? Response: সূর্য থেকে আলো আসতে কত সময় লাগ (repeats the question) The expected answer is 8 mins 20 seconds |
Falcon 180B
(see image) |
*These are cherry-picked examples as LLMs continue to improve their quality.
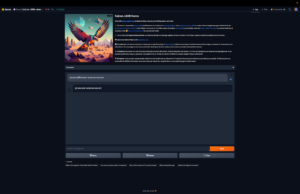
Figure 1: Falcon 180 B response for Bangla prompt
Text 2 Image LLMs
The problem is exacerbated more in Stable diffusion models, even for resource-rich languages
When we prompt Stable diffusion turbo [3] in English “Deer walking on dirt road”, the image matches the meaning, but when the same sentence is prompted in Chinese, “鹿在土路上行走” the image has no deer. It is irrelevant to the prompt.

Figure 2: Comparison of SDXL turbo response to a prompt in English and Mandarin of the same meaning
Focus on solution to improve prompting without pre-training or fine-tuning :
Several solutions have been proposed to address the language barrier in LLMs:
- Training an LLM from scratch: Building a language-specific LLM can solve the training data disparity issue, but it comes with a high cost, often reaching millions of dollars.
- Fine-tuning [4] : A more cost-effective approach involves fine-tuning an existing LLM to a domain-specific task in the underrepresented language. This process includes preparing a comprehensive dataset in the target language, expanding the token vocabulary, continual [6] pre-training on a language-specific corpus, and adding LORA [5] adapters to the LLM. While cheaper than building from scratch, fine-tuning can still cost tens of thousands of dollars.
- Translation layer: This solution involves building a translation layer around an existing LLM. Non-English prompts are translated into English using an off-the-shelf translation API, processed by the LLM, and the generated response is then translated back into the target language. This approach leverages the strengths of existing LLMs while accommodating non-English users.
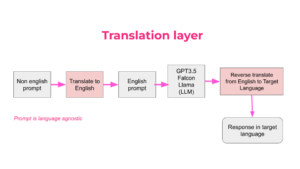
Figure 3 : Solution of translating the prompt to English and reverse translate later
Adding a Translation layer offers several benefits, such as the ability to use existing LLMs for localized applications without the need for expensive fine-tuning or building from scratch. It also unlocks the potential for building localized RAG applications, which can have a significant impact on last-mile users.
However, this approach also has its drawbacks.
- The prompt has to be language-agnostic. For example, if an Arabic speaker prompts the LLM to write a poem, translating that prompt to English, writing a poem, and reverse translating back to Arabic will not work. What’s rhyming in English may or may not rhyme in Arabic
- The performance of the system heavily depends on the quality of the translation layer. Poorly translated prompts can lead to suboptimal results.
- For Text-2-Image diffusion models, language captures the culture too. Translated prompts may generate images that are anglosphere-centric and not necessarily capture cultural context of the non-English prompt.
- Translation Augmented Generation
Instead of translating the prompt to English, we use another LLM (eg. GPT 3.5) to do two things 1) Detect the language and translate to English and 2) Add metadata in English based on a chain of thought prompting, 3) output the prompt in the original language
The final prompt would be a concatenation of
“english translation” + “metadata” + “prompt in original language”
Stable diffusion is able to
- Get meaning from English and context from metadata
- Cultural nuance the original language characters thereby it’s able to generate a more relevant and meaningful image.
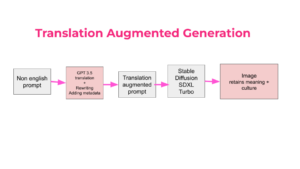
Figure 4: Translation Augmented Generation
Without Translation Augmentation
| English | Same prompt in Hindi |
| Prompt: A girl standing in front of a tree dressed for a special occasion. | Prompt: विशेष अवसर के लिए तैयार होकर एक पेड़ के सामने खड़ी लड़की (no tree, not a singular girl) |
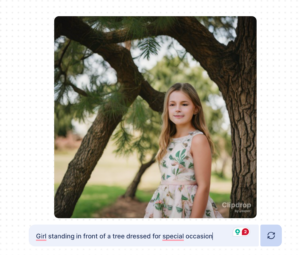 |
 |
Figure 5: Without Translation Augmented Generation
With Translation Augmentation (a prompt engineering technique)
Eg. https://chat.openai.com/share/5a948b76-1e53-4011-8760-69dea69182a6
GPT 3.5 does following processing
{
“input_prompt”: “विशेष अवसर के लिए तैयार होकर एक पेड़ के सामने खड़ी लड़की”,
“english_translation”: “A girl standing in front of a tree, ready for a special occasion”,
“chain_of_thought”: “Girl anticipates, tree symbolizes life’s growth, special moment awaits.”
}
| Hindi |
| Prompt sent to Stable diffusion
“A girl standing in front of a tree, ready for a special occasion Girl anticipates, tree symbolizes life’s growth, special moment awaits विशेष अवसर के लिए तैयार होकर एक पेड़ के सामने खड़ी लड़की” |
 |
Figure 6: With Translation Augmented Generation
A tradeoff here is an increase in the number of tokens processed by the diffusion model.
Conclusion
Translation Augmented Generation presents a promising solution to bridge the language gap in LLM for prompts to Text-2-Image Diffusion models. This can be a stop-gap prompt engineering technique that AI engineers can use as LLMs improve the representation of low-resource languages. By building a simple translation layer, users can access the power of existing LLMs without the need for expensive fine-tuning or building from scratch. While this approach has its limitations, it opens up new opportunities for building localized applications and extending the reach of LLMs to a broader, multilingual user base. As large language models evolve, it is crucial to address the challenges faced by non-English users and include multiple languages in model training to encompass the diverse linguistic landscape of our world.
References:
- https://commoncrawl.org
- Non-English prompt Examples from GPT3.5
- SDXL Turbo from clipdrop https://clipdrop.co/stable-diffusion-turbo
- Finetuning https://platform.openai.com/docs/guides/fine-tuning
- LORA: Low-rank adaptation of LLMs https://arxiv.org/abs/2106.09685
- Continual Pre-Training of Language models https://arxiv.org/abs/2302.03241
- Low-resource languages https://arxiv.org/abs/2006.07264
Open Source Summit Talk: https://ossna2024.sched.com/event/1aBOj
Acknowledgements:
We would like to thank Sachin Varghese, Santhosh Sachindran and the rest of the Gen AI Commons for thoughtful review comments.