



Authors:
- Revathy Venkataramanan, AI Institute at University of South Carolina & AI Research Lab at Hewlett Packard Labs (revathy@email.sc.edu, revathy.venkataramanan@hpe.com)
- Aalap Tripathy, Principal Research Engineer, AI Research Lab at Hewlett Packard Labs (aalap.tripathy@hpe.com)
- Ali Hashmi, Senior Data Scientist, IBM Consulting (ahashmi@us.ibm.com)
Introduction
Enhancing AI transparency is crucial for understanding and ensuring the responsible use of artificial intelligence. One key aspect of achieving this transparency is developing robust ontologies. This article explores the importance of designing an ontology to facilitate AI transparency, focusing on data lineage, data provenance, and metadata representation throughout the AI workflow.
Understanding Data Lineage and Data Provenance: Data lineage involves tracking the flow of data over time within an AI workflow, while data provenance aims to trace the origin of specific pieces of information. Both are vital components for ensuring transparency and accountability in AI systems.
The Need for Ontologies: To effectively capture and represent data lineage, data provenance, and other metadata within AI workflows, it is essential to create appropriate ontologies. These ontologies serve as structured frameworks for organizing and categorizing information, ensuring that relevant data is properly documented and accessible.
Ontologies are semantic data structures that define concepts, their relationships, and associated properties. They serve as a formal framework for Knowledge Graphs (KGs), information stores based on semantic networks. Think of an ontology as akin to the schema of a relational database. However, KGs surpass traditional databases by capturing the meaning of real-world concepts and their implicit connections. KGs play a vital role in achieving data analysis transparency, reasoning, and explainability. Numerous open-source KGs have been developed through crowd-sourcing efforts and found applications in various research domains. Examples of generic KGs include WikiData, DBPedia, and ConceptNet, while specialized KGs exist for fields like healthcare, autonomous driving, and food. Moreover, KGs have been created to represent scenes in autonomous driving and workflow procedures in manufacturing. With their structured semantic understanding of entities, these knowledge graphs enable machines to seamlessly interpret complex information.
How to design an ontology to aid in AI transparency?
Data lineage is the process of tracking the flow of data over time. Data provenance is the ability to trace the origin of a piece of information. While tools can be created to capture data lineage, and provenance across modern AI workflows, it is equally important to create appropriate ontologies to represent such metadata information. This could include artifacts generated during the course of data preparation, model training/tuning and model deployment, as well as the models themselves. An appropriate ontology should ideally encompass the end-to-end pipeline likely composed of multiple steps or stages. Each stage may have multiple executions, producing various artifacts (models, input/output/intermediate datasets, etc.) and generating various metrics. Typically, the most accurate execution may be selected for retention and publication, and it can be documented via a Model Card , Factsheet or a Service Card. It is important to represent all this intermediate metadata with an appropriate ontology for reproducibility and transparency.
Existing work on Ontologies
Existing work on ontology MLSchema proposed an ontology that is suitable for OpenML tasks. DeepSciKG built an ontology that supports multimodal information extracted from papers such as code, figures, and other textual information extracted from the paper. OpenLineage has a data lineage collection and analysis framework, although it is not represented as a formal ontology. However, there is a need for a universal pipeline schema that can integrate metadata from various sources. Unlike existing work, a pipeline schema captures the metadata of a pipeline’s components such as dataset, dataset preprocessing, model and hyperparameter selection, training, testing, and deployment.
A Common Metadata Ontology to model AI pipeline lifecycle Common Metadata Ontology (CMO) is specifically designed to capture the pipeline-centric metadata of AI pipelines. It consists of nodes to represent a pipeline, components of a pipeline (stages), relationships to capture interaction among pipeline entities and properties, artifacts (models and intermediate datasets), and metrics produced by individual executions. Interoperability of diverse metadata elements offers the flexibility to incorporate various executions implemented for each stage, such as dataset preprocessing, feature engineering, training (including HPO), testing, and evaluation. CMO has been used to curate and integrate pipeline metadata from open source AI workflow repositories such as Papers-with-code, OpenML, and Huggingface to create a comprehensive AI Pipeline Metadata Knowledge Graph (MKG). Finally, CMO facilitates the inclusion of additional semantic and statistical properties to enhance the richness and comprehensiveness of the metadata associated with ML pipelines.
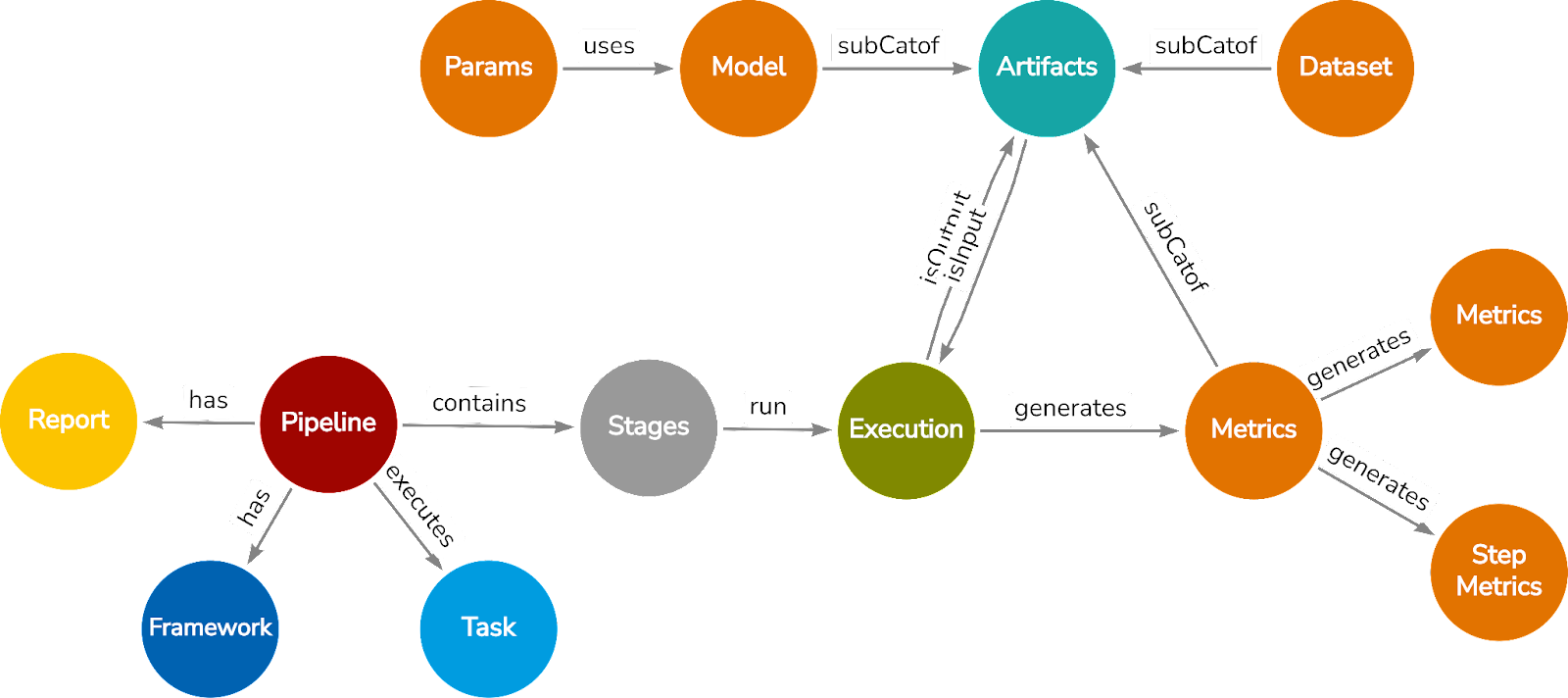 Figure 1: The nodes represent the pipeline and the components of a pipeline which consists of stages, executions, report, framework, intermediate artifacts, and metrics.
Figure 1: The nodes represent the pipeline and the components of a pipeline which consists of stages, executions, report, framework, intermediate artifacts, and metrics.
Node types in Figure 1 can be distinguished via the following table:

A related but focused example of an ontology applied to the understanding of neural networks is presented below in Figure 2. This work by Nguyen et. al. seeks to build on the FAIR principles: guidelines to improve the Findability, Accessibility, Interoperability, and Reuse of digital assets.
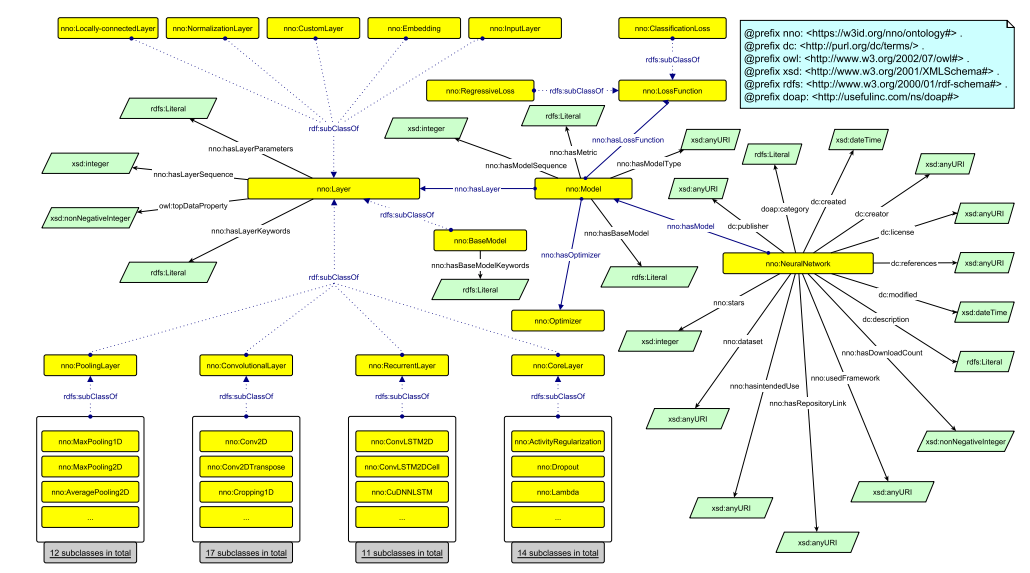 Figure 2: FAIRNets Ontology to model metadata for neural network models
Figure 2: FAIRNets Ontology to model metadata for neural network models
Discussion of transparency & ontologies
Tools like Common Metadata Framework (CMF) can collect and store information associated with Machine Learning (ML) pipelines and represent them using the Common Metadata Ontology naturally. CMF adopts a data-first approach: all artifacts (such as datasets, ML models, and performance metrics) recorded by the framework are versioned and identified by their content hash. Recording entire pipelines has an inherent advantage in capturing the entire lifecycle of an AI experiment – from data capture, pre-processing, different training runs, deployment, validation, and monitoring, as well as fairness, explainability, and robustness testing. CMF‘s data model is a manifestation of CMO which aids in transparency as is shown with the following examples.
Practical example
CMF + AI Fairness 360
We describe how a real-world bias mitigation use case can be aided by the use of open source tools and a common metadata ontology in Figure 3. Two teams are working on mitigating the bias in an Automatic Gender Classification pipeline. Whereas the first team uses a reweighing algorithm to transform the dataset, the second team implements a more recent adversarial debiasing technique both available in AI Fairness 360.
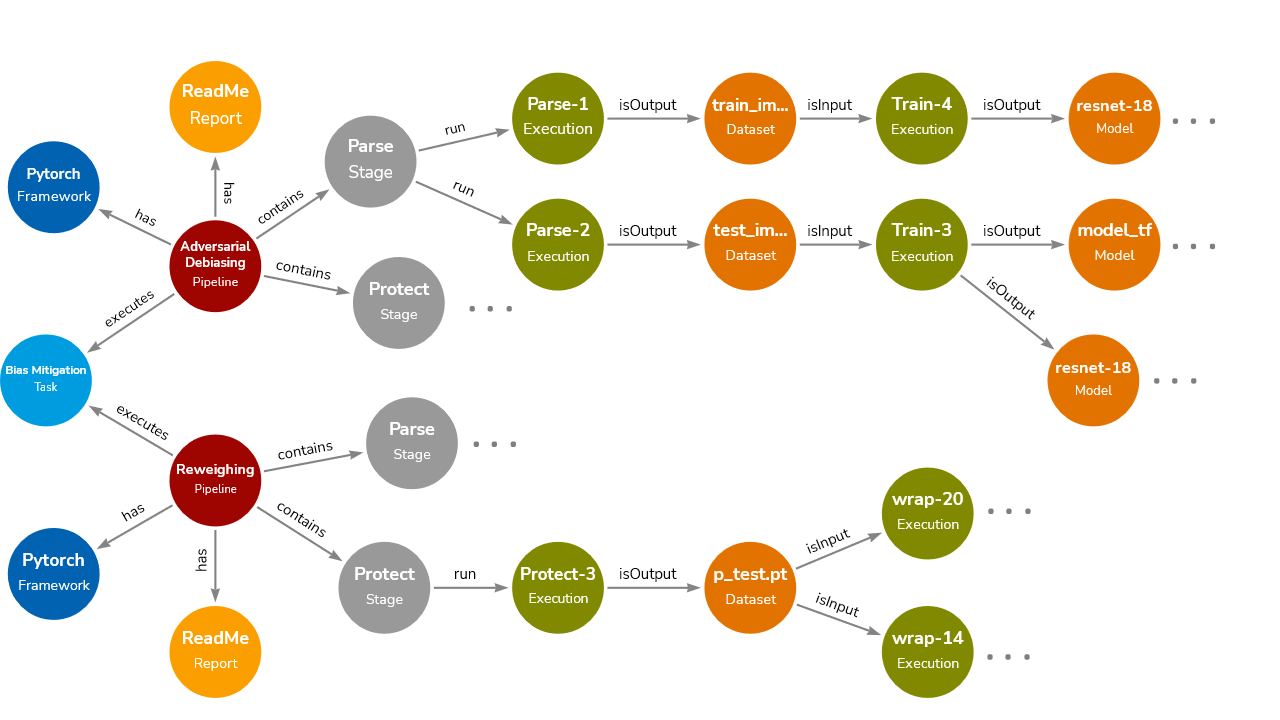 Figure 3: For the Bias Mitigation task (light blue node), two pipelines (red nodes) namely, Adversarial Debiasing and Reweighing have been executed. Each pipeline consists of its stages, executions, and artifacts. The figure shows a subset of a complex pipeline for brevity.
Figure 3: For the Bias Mitigation task (light blue node), two pipelines (red nodes) namely, Adversarial Debiasing and Reweighing have been executed. Each pipeline consists of its stages, executions, and artifacts. The figure shows a subset of a complex pipeline for brevity.
Representation of Papers-with-code pipeline using CMO
Public sources such as Papers-with-code, Huggingface, and OpenML expose the metadata of already executed pipelines which can be unified and represented using CMO. CMO provides a universal structure to represent AI pipeline metadata to perform downstream tasks such as semantic search or recommendation. Figure 4 shows a pipeline from Papers-with-code titled “Robust outlier detection by de-biasing VAE likelihoods” executed for the “Outlier Detection” task. The model used in the pipeline was “Variational Autoencoder”. Several datasets were used in the pipeline implementation which are as follows: (i) German Traffic Sign, (ii) Street View House Numbers, and (iii) CelebFaces Attributes dataset. The corresponding hyperparameters used and the metrics generated as a result of execution are shown in Figure 4.
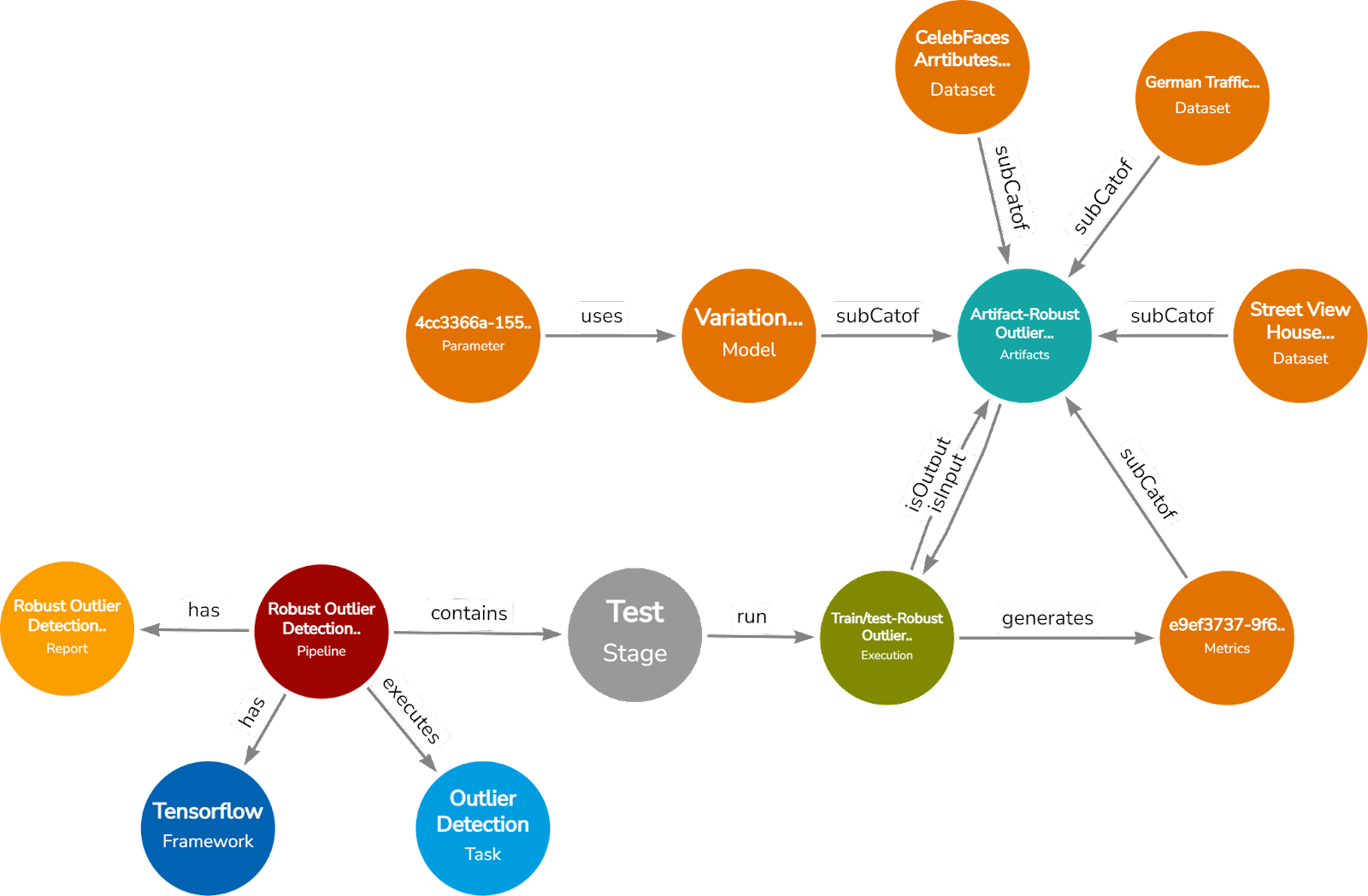 Figure 4: Pipeline executed for Outlier Detection task. The sample datapoint is from Papers-with-code.
Figure 4: Pipeline executed for Outlier Detection task. The sample datapoint is from Papers-with-code.
As knowledge graphs can capture semantics and implicit associations among entities, representing pipeline metadata using them can enable context-aware recommendations. For example, deep learning tasks such as 3D object segmentation and 2D object detection do not explicitly mention that these two are computer vision-based tasks. Representing these tasks using CMO with their respective properties can capture these implicit meanings. Similarly, a KG-based approach will be able to extract from the class labels that Flowers-102 is an image-based dataset that is representative of flowers whereas Sentiment-140 is a text-based dataset to classify sentiments. Such implicit understanding can be provided by knowledge graphs which enable transparency, reasoning, and explainability of the data. Currently, many entities comprising AI pipelines still need work to fully catalog their complete metadata, and these are actively being computed or generated. The curation of such information through crowdsourcing from domain experts will significantly enhance the semantic search and recommendation capabilities of metadata KGs.
Conclusion – Quick Summary
Transparency will continue to be a vital goal of AI/ML methods and systems, especially as the frontiers of this field continue to advance. Ontologies, such as CMO, and their implementation, with a framework such as CMF, represent a key component to delivering transparent, explainable, and successful AI/ML. The solutions presented here are still in draft as of this writing, and we invite you and anyone else with interest to join the collaboration. Contribute to these projects and help advance their progress!
LF AI & Data Resources
- Learn about Membership opportunities
- Explore the interactive landscape
- Check out our technical projects
- Join us at upcoming events
- Read the latest announcements on the blog
- Subscribe to the mailing lists
- Follow us on Twitter or LinkedIn