



 DocArray is a Python library expertly crafted for representing, transmitting, storing, and retrieving multimodal data. Tailored for developing multimodal AI applications, its design guarantees seamless integration with the extensive Python and machine learning ecosystems. DocArray recently submitted its request to become an incubation project, met the requirements, and joined 26 other projects under the LF AI & Data Foundation.
DocArray is a Python library expertly crafted for representing, transmitting, storing, and retrieving multimodal data. Tailored for developing multimodal AI applications, its design guarantees seamless integration with the extensive Python and machine learning ecosystems. DocArray recently submitted its request to become an incubation project, met the requirements, and joined 26 other projects under the LF AI & Data Foundation.
Three distinct project lifecycles exist for progress within the LF AI & Data Foundation. These life cycles help track the projects’ progress and success, ensuring they receive appropriate resources and support to thrive.
Once a project has demonstrated sustainability, growth, and maturity, it progresses to the incubation stage and obtains affirmative votes from both the Technical Advisory Council (TAC) and the Governing Board (GB) for incubation and graduated projects.
Key highlights that the DocArray team has been working on include:
- Completion of the refactoring of the library to provide dynamic schemas while keeping all power of serialization capabilities.
- The integration with different vectorDBs, like weaviate, qdrant, ElasticSearch, Redis
- Integration in the LangChain ecosystem which led to being used in Andrew Ng course.
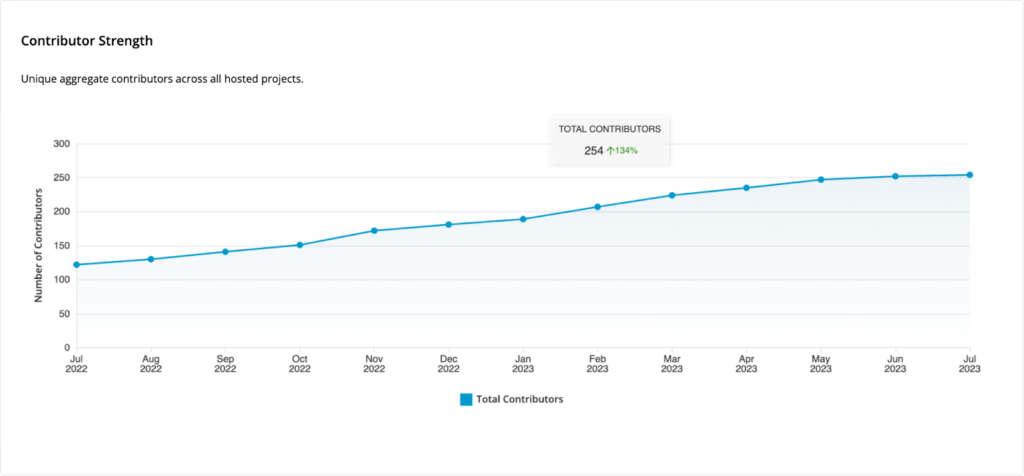
Additionally, DocArray has enjoyed increased popularity and contributions during the past year.
-
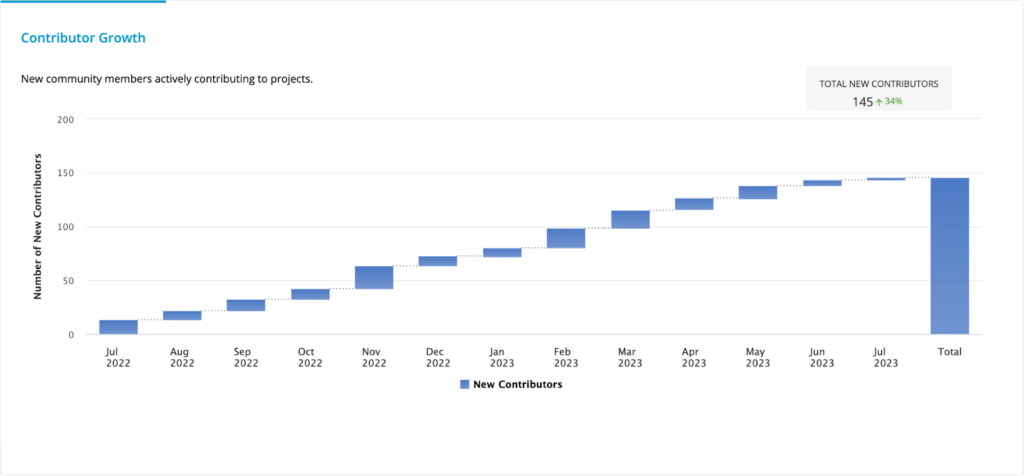
- Contributor Growth is up 34%
-
- Commits up 127%
-
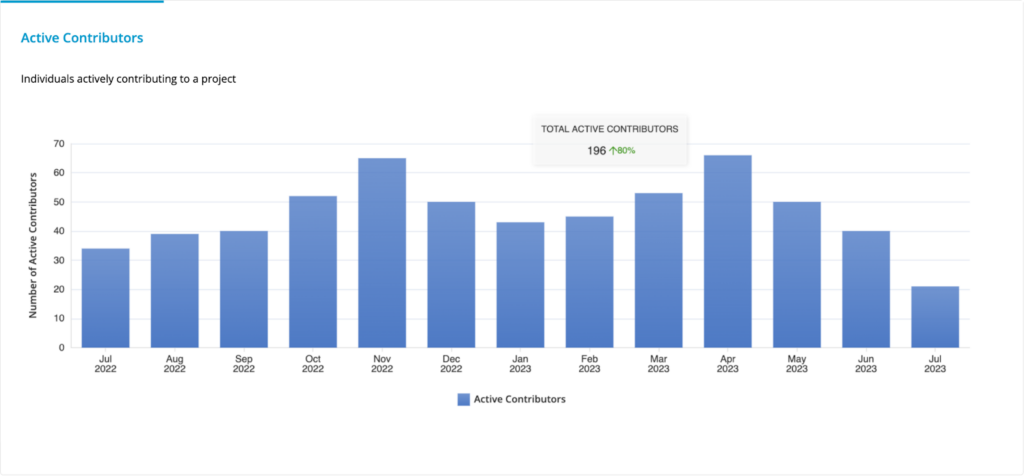
- Contributors increased 80%
Additional features of DocArray include:
- Offers native support for NumPy, PyTorch, TensorFlow, and JAX, catering specifically to model training scenarios.
- Based on Pydantic, and instantly compatible with web and microservice frameworks like FastAPI and Jina.
- Provides support for vector databases such as Weaviate, Qdrant, ElasticSearch, Redis, and HNSWLib.
- Allows data transmission as JSON over HTTP or as Protobuf over gRPC.
Please join us and congratulate the DocArray community and we invite you to learn more about their work.