


By: Adrián González Sánchez and Ofer Hermoni
Introduction
In the rapidly evolving landscape of Artificial Intelligence (AI), the buzz is louder than ever. Since our last exploration into the realm of accountable AI, the world has ridden the wave of Generative AI, with its potential and implications now a topic of global discourse. In this post, we take a deep dive into the key developments and trends in AI regulation, open-source technology’s role in the AI ecosystem, and the pressing need for clear guidelines that emphasize transparency and accountability.
As we explore these complex issues, we aim to paint a vivid picture of where we stand today and where we need to head to foster a responsible, accountable, and effective AI ecosystem. Whether you’re a policymaker, an industry expert, an academic, or a curious observer, this post is designed to offer insights and spark conversations about the future of AI governance.
Part 1 – General AI context, by Adrián González Sánchez
Catching up with Generative AI
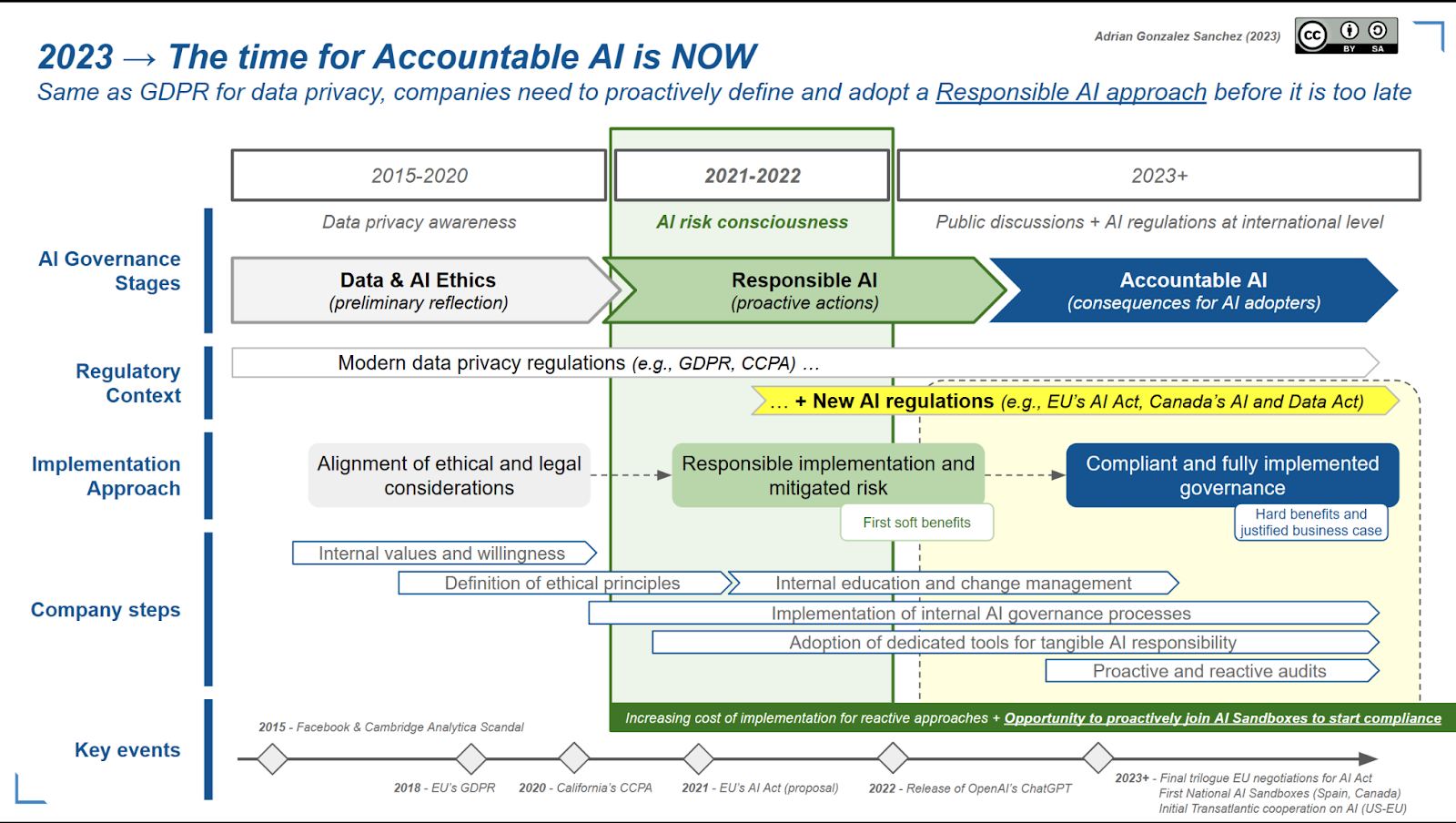
It’s been eighteen months since our initial LF AI & Data blog about accountable AI, and the case for responsible and accountable AI has become even more relevant today. The Generative AI wave has taken the world by storm, with discussions at all levels including politics, academia, industry, and regulators. Even the general public is coming to understand the power and implications of AI, thanks to increasingly accessible AI tools like ChatGPT.
In this context, we could affirm that the timing we anticipated last year for the AI awareness phase was pretty accurate. In a perfect scenario, 2021-22 was indeed the best period to start preparing internal AI governance for the organizations. If that was the case for everyone, the first building blocks would have been already there, for adopting teams to analyze how to adopt Generative AI tools, based on a pre-established series of processes, internal Responsible AI (RAI) champions, etc. But the reality is that the new era of Generative AI took most organizations unprepared, with a changing context that includes new AI regulations and causing inadvertent individual or societal harm. The 2023-2024 period is now the new window of opportunity for most of the companies to apply the technology to their internal AI governance before AI accountability comes into play (for example, with monetary fines and/or personal C-Suite liability, same as EU’s GDPR)
What is new with AI regulations?
The level of progress we’ve seen could be seen as substantial or meager, depending on one’s perspective. The previous article compared Data Privacy regulations such as CCPA and GDPR with the upcoming AI regulation, as a way to anticipate the adoption and compliance process that companies will need to follow during the next few years. The reality is that the preparation of these regulations has taken some time, but now things are accelerating because most of the different players (e.g., policymakers, corporations, academia, the general public, etc.) agree that regulation is crucial.
Part 1 mentioned the “very” European EU AI Act (because of its pro-regulation approach with forbidden cases and focus on fundamental rights) as the main reference, and it is indeed the first case at the international level. What’s new here? The original 2021 draft document finally evolved and entered the review and amendments phase, with a major milestone in May 2023 when the mandate for draft negotiation finally started. Now there is a negotiation phase between the key EU stakeholders (Commission, Parlament, States) to agree on the final version of the regulation. At this point, it is already catching up with the latest Generative AI developments which is including additional transparency measures for training data and content.
Meanwhile, the rest of the world is also taking steps toward AI regulations. There is mounting pressure in the United States to create a Federal Law for artificial intelligence. Both academia and industry are calling for such regulation to be put in place, a sentiment reflected in a recent shared statement on AI risk.
Even more, both the USA and the EU are planning to quickly develop an international AI code of conduct, with no legal implications. Any company or individual subscribing to the code has no legal obligations, but just the willingness to adhere to it and do things in a proper way). This is a preliminary measure that may help while regulations get in place and an interesting declaration of intentions with convergence between the American and European principles.
We also see this trend in Canada with the current development of their AI and Data Act at the federal level, and the provincial Loi 25 in Quebec (which focuses on data protection, but includes measures for automated decision-making), the UK (and their opportunity to create a different flavor of what EU is doing with the AI Act), and China (including a new series of “interim measures for management of generative AI”). At the same time, there were some discussions for copyright-related topics regarding Generative AI, and the ability and right to collect proprietary data to train new massive models, including those from the US Copyright Office, and the precedent set by the Japanese Government to allow it.
It’s here that the importance of worldwide collaboration on potential global regulation of AI cannot be overstated. We need only look to the fragmented approach to privacy regulation as an example of how a lack of global coordination can lead to confusion and compliance challenges for companies operating across borders.
Different countries and regions implemented their privacy laws, such as the EU’s General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA, now CPRA) in the United States. These varying regulations have created a complex tapestry of requirements that businesses must navigate, causing frustration, inefficiency, and potentially stifling innovation. The lack of harmony in privacy laws has arguably led to unnecessary complexity, without necessarily enhancing data privacy.
In the realm of AI regulation, we have an opportunity to learn from these experiences and strive for a more coordinated approach. A globally harmonized regulatory framework would offer clearer guidance for organizations, reduce administrative burden, and ultimately foster a healthy, responsible global AI ecosystem. As we move forward, international collaboration is crucial to ensure that the promise of AI can be realized without compromising the values we collectively uphold.
Meanwhile, there are a few interesting initiatives for AI regulations and accountability:
- Spain-EU’s first regulatory AI sandbox, starting this year
- Canada’s AI Certification Pilot, with Responsible AI Institute and Standards Council of Canada
- ForHumanity’s AI Act Auditor training (free training, paid certification)
Summarizing, a very evolving and challenging moment, but still leading to what we previously defined as the era of accountable AI. Same to GDPR and other data privacy regulations, companies will need to align and comply with all applicable AI regulations, depending on their geographic activities.
Part 2 – Open Source and Guidelines, by Ofer Hermoni
Open Source in the Crosshairs
The changing regulatory landscape brings unique challenges and considerations for the open-source community. Within the context of The Linux Foundation’s work, we’re compelled to grapple with questions such as: How are these regulatory shifts impacting open-source projects, regardless of whether they stem from individual contributors or corporate initiatives? How should regulatory approaches differ, if at all, between these two sources?
Finding the answers to these questions isn’t straightforward, but it’s apparent that open-source technology must be a central concern in the march toward global regulation. A case in point is the EU AI Act, which initially included open source, later removed it, and eventually reintegrated it. This pattern underscores the important realization that AI technology risks are not tied to whether the source is open or closed, necessitating uniform regulations for all types of AI technology.
This understanding underscores the need for regulations that are inclusive, adaptable, and resilient to the rapidly evolving AI landscape. As this crucial conversation unfolds, we must bear in mind that all technology sources, open or closed, play a role in shaping the AI ecosystem, and any effective regulatory framework must recognize this diversity.
Initial Guidelines to Earn Trust
As we progress further into the AI era, it’s crucial to establish some initial guidelines to earn trust.
We must underscore the need to provide data lineage and provenance with our outputs. Content grounding is critical to encourage trust. “This output came from these sources of data that we trust for the following reasons…” One can do this by pairing a Large Language model with something that offers this kind of content grounding like an ontology or a symantec search.
As USAID states so eloquently in their AI Action plan, we need to empower more people to be able to build their own AIs such that they better reflect the communities that they serve. How can we offer power to trusted members of communities like librarians to build ontologies that reflect the values of their own communities given their cultural context? What kinds of tools can be built for them to be able to create these ontologies and share/sell them to other communities? We have moved far beyond asking the question “Do I trust this AI?” to “Does the worldview being represented in this AI match my own?”
We must address the huge cost of energy used to train these models.
We must address the cybersecurity concerns being presented in these models. LLMs are being used now to phish, scam, and spam without an end user ever understanding what is happening.
We must make sure that all people have access to training so as to better understand how to be far more critical consumers of AI. When one of our members presented to 400 girl scout troops this past May, she asked the girls to begin naming ways in which they felt that AI was unfair or “just plain wrong”. The girls were quite prolific in their responses!
=> A girl from Nepal asked, “When I use an Art Generator to draw me 2 children in the Nepalese mountains, it drew two blond kids! They look nothing like my people!”
=> “When I use Dall-e to create portraits of my mom and me it draws us in various states of undress whereas my brothers and dad get to be in astronaut suits!”
Corporations today want to use Generative AI directly with what could be very vulnerable groups of people to offer them counsel on everything from health advice to giving suggestions on where to move to in order to be more prosperous and “happy”. If we are not fully aware of the consequences of very biased outputs and do not have AI governance in place with humans in the loop to assess and mitigate risks, people- including our very most vulnerable- will be hurt.
Crucially, we must also establish a clear distinction between human-generated and AI-generated content. This calls for a comprehensive ‘marking system’, where AI-produced content is appropriately identified. This measure is not just about transparency; it’s about empowering us to discern and make informed decisions based on the origin of the information.
Moreover, we must strive for broader transparency rules that govern the deployment of AI. This includes clarity about the underlying AI models – their purpose, the data on which they were trained, and any inherent biases they might possess. Transparency should not be an afterthought; it’s the bedrock upon which we can build trust in AI systems.
We, therefore, appeal to all stakeholders – governments, businesses, academia, and the public – to contribute to this discourse and advocate for these foundational steps in holistic, multi-disciplinary AI education starting in K-12 and AI regulation. It is through this collaborative effort that we can pave the way for marked AI-generated content and robust transparency rules, thereby shaping a more secure, accountable, and trustworthy AI environment for all.
Summary
This post examines the recent progress and challenges in AI regulation, discussing the global drive toward formulating rules for responsible AI deployment. With a particular focus on the roles of both the open-source community and AI-generated content, the post delves into the pressing need for a uniform, inclusive, and adaptable regulatory framework. The discussion underscores the importance of transparency, urging for a collective approach among stakeholders – governments, businesses, academia, and the public – to create a more accountable and trustworthy AI environment.