

LF AI & Data Foundation—the organization building an ecosystem to sustain open source innovation in artificial intelligence (AI) and data open source projects, today is announcing DocArray as its latest Sandbox Project.

“We’re excited to welcome DocArray as our latest Sandbox project in LF AI & Data. The project presents a unique opportunity to address the challenge of designing and implementing a suitable structure for unstructured data,” said Dr. Ibrahim Haddad, Executive Director of LF AI & Data. “LF AI & Data provides its hosted projects, such as DocArray, with a suite of services to enable the growth of the developer community and the adoptees of the project, and foster collaboration and technical integration across hosted projects in support of the open source AI ecosystem. DocArray is a natural fit for LF AI & Data and we’re looking forward to supporting the project and its community.”
“We believe that the multimodal AI is the next step and DocArray makes it easy to work with the multimodal data. As the maintenance team of DocArray, we are so excited to see DocArray joining LF AI & Data and we are looking forward to working with the OSS community to make DocArray a one-stop solution for any data type and any vector database,” said Dr. Nan Wang. CTO & Co-founder of Jina AI.
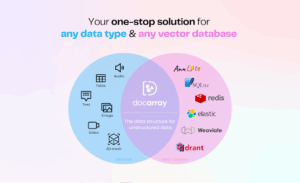
Contributed by Jina AI, DocArray is a library for nested, unstructured, multimodal data in transit, including text, image, audio, video, 3D mesh, and more. It allows deep-learning engineers to efficiently process, embed, search, recommend, store, and transfer the multi-modal data with a Pythonic API. Some features of the project include:
- Door to cross-/multi-modal world: super-expressive data structure for representing complicated/mixed/nested text, image, video, audio, 3D mesh data.
- Data science powerhouse: greatly accelerate data scientists’ work on embedding, k-NN matching, querying, visualizing, evaluating via Torch/TensorFlow/ONNX/PaddlePaddle on CPU/GPU.
- Data in transit: optimized for network communication, ready-to-wire at any time with fast and compressed serialization in Protobuf, bytes, base64, JSON, CSV, DataFrame. Perfect for streaming and out-of-memory data.
- One-stop k-NN: Unified and consistent API for mainstream vector databases that allows nearest neighbor search including Elasticsearch, Redis, ANNLite, Qdrant, Weaviate.
- For modern apps: GraphQL support makes your server versatile on request and response; built-in data validation and JSON Schema (OpenAPI) help you build reliable web services.
- Pythonic experience: designed to be as easy as a Python list. If you know how to Python, you know how to DocArray. Intuitive idioms and type annotation simplify the code you write.
- Integrate with IDE: pretty-print and visualization on Jupyter notebook & Google Colab; comprehensive auto-complete and type hint in PyCharm & VS Code.
To date, DocArray boasts 1,200+ GitHub stars, 40+ contributors, 2,000+ monthly active docs users, and 100,000+ monthly downloads. Several existing LF AI & Data projects are potential collaborators, which will further strengthen the AI & Data ecosystem.
LF AI & Data supports projects via a wide range of services, and the first step is joining as a Sandbox Project. Learn more about DocArray on their GitHub and join the DocArray-Announce Mailing List and DocArray-Technical-Discuss Mailing List.
A warm welcome to DocArray! We are excited to add this project to our portfolio and look forward to its future success in our community and beyond. To learn about how to host an open source project with us, visit the LF AI & Data website.
DocArray Key Links
LF AI & Data Resources
- Learn about membership opportunities
- Explore the interactive landscape
- Check out our technical projects
- Join us at upcoming events
- Read the latest announcements on the blog
- Subscribe to the mailing lists
- Follow us on Twitter or LinkedIn
- Access other resources on LF AI & Data’s GitHub or Wiki