

Guest Author, Dr. Jagreet Kaur

Keywords
| Keyword | Description |
| DL | Deep Learning |
| ML | Machine Learning |
| U.S | United State |
| EDA | Exploratory Data Analysis |
Abstract
Over the last few years, society has begun to grapple with how human bias might infiltrate artificial intelligence systems with potentially disastrous results.
When the whole world is moving towards AI and adapting it for their operation, being aware of these risks, their detection and reduction is very urgent.
Bias can move to algorithms in several ways. AI applications make decisions according to the data they used to train, which may contain biased human decisions and historical/social inequities even if it does not contain any sensitive variable such as gender, race, caste, etc. Thus it reduces the AI potential for business and society. It can mislead society by giving biased results.
Bias is our responsibility; therefore, it must ensure that AI systems are fair and perform responsibly. Various approaches can be implemented to detect and mitigate such bias. This paper will also discuss a tool named AIF360 that can detect and mitigate bias. It also shares an example of a diabetes detection system in which first bias is detected and then mitigated by using one of the provided mitigation algorithms of AIF360.
Today’s reality
AI applications are using ML/DL for making predictions. ML identifies the statistical patterns from historically collected data to make predictions generated by many instances that might be affected by several human and structural biases. ML algorithms can amplify these inequities and can generate unfair results.
For instance, U.S. health practitioners also use Artificial Intelligence algorithms to guide health decisions. Still, researchers at UC Berkeley, Obermeyer et al. find racial bias in that algorithm, unintentionally perpetuating existing inequality. An algorithm assigned the same level of risk to the black patient yet sicker than white patients. It gave higher risk scores to the white patients, thus more likely to be selected for extra care. As a result, it reduces the more than half of the black patients identified for extra care compared to white.
The main reason for bias in that algorithm is it used health costs rather than illness for health needs. Less money is spent on Black patients than on white, yet they have the same level of need. Thus, the algorithm falsely considers that black patients are healthier than white patients for the same disease.

Figure 1.1 Racial Bias in Healthcare
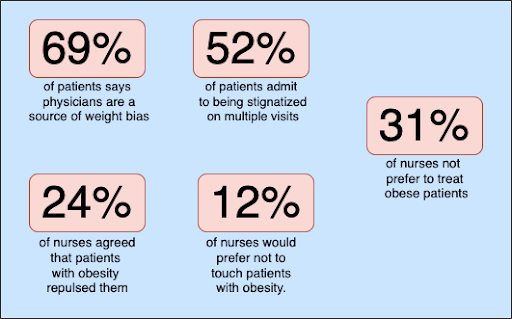
Figure 1.1 End weight Bias in Healthcare
Using Ethical AI to overcome such issues and find a solution to reduce these biases is very important.
Challenges
A solution is required to resolve the bias issues of data and ML algorithms that can detect and mitigate the bias. There is a need to answer the following questions:
- How does partial data affect the output of the Machine Learning model, and why should it be mitigated?
- How to ensure that the model is generating fair results?
First, understanding how the bias arises for detecting and mitigating bias is required, which is a challenging task. Secondly, there are no standard practices developed in data science to detect it. So, users have to learn new tools like AIF360, What if the tool, and also understand how these are implemented.
Moreover, selecting protected, favorable and unfavorable attributes and preparing a dataset for different tools is challenging. And, It is all new in the AI and machine learning domain.
Fairness AI In Healthcare
There are so many machine learning models in healthcare being developed, deployed, and pitched; one way to ensure that these AI tools don’t worsen health inequalities is to incorporate equity into the design of AI tools. Addressing equity in AI is not an afterthought but rather a core of how we implement Artificial Intelligence in our health system.
Why do we need Fairness AI In Healthcare?
Artificial Intelligence in Healthcare can raise ethical issues and harm patients by not providing intended outcomes. Therefore it is necessary to use Ethical Artificial Intelligence in the health industry. Akira AI delivers a platform for AI applications that follow AI ethics and respect human values and morals. The system obeys the following principles:
- Social Wellbeing
- Avoid Unfair Bias
- Reliable and Safe
- Governable
- Value alignment
- Human-centered AI
Approach
There have been numerous attempts to reduce bias in artificial intelligence to maintain fairness in machine learning projects. Here we will discuss one of the practical approaches for the diabetes prediction system. An algorithm predicts whether a patient has diabetes based on health-related details such as BMI (Body Mass Index), blood pressure, Insulin, etc. The system is only for females as the dataset used to make this system exclusively belongs to the females.
Checking and mitigating bias in diabetes prediction systems is essential. There is a feature, “Age,” that the system is considering for making decisions. Having bias based on the age for checking a disease is not a good approach. Because if a system gives a biased result and doesn’t spot the disease of a person who belongs to a particular age group, it may worsen their health condition.
Understanding data
EDA helps analyze the data patterns and trends that tell a lot about data. We got insights about the data distribution and the feature columns through histograms through EDA.
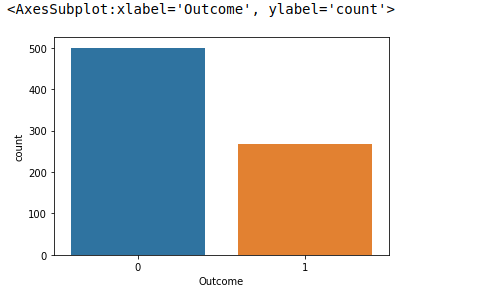
Figure 1.1 Distribution of Target column
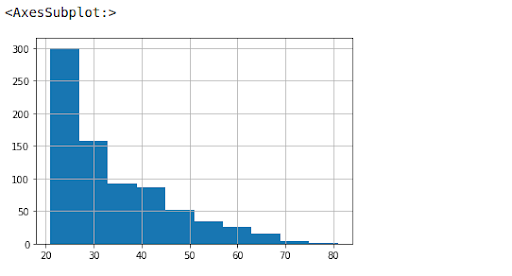
As shown in Figure 1.2, data contains fewer data of age 40 – 80 compared to 20-40, so having bias while checking for older ones may have unfair results.
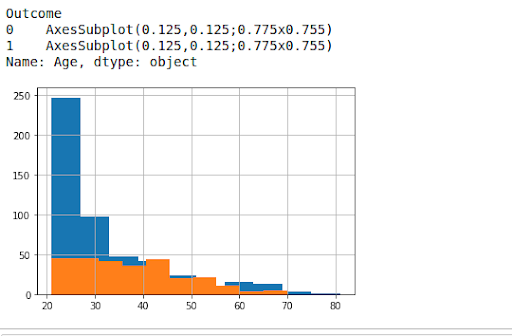
Figure 1.3 Distribution of Age w.r.t Target column
The above plots[Figure 1.3] show age and target column distribution. There is no proper data collection and distribution of races from the initial findings that may have led to the bias.
As shown in the above figures, there is an improper distribution of the above columns, so it is preferred to check bias.
Bias detection
AIF360 is an open-source package provided by IBM that provides various techniques to detect bias. We are using BinaryLabelDatasetMetric provided by the aif360 library to detect bias. It used two terms.
- Privileged: This group contains a person of age equal to and greater than 25.
- Unprivileged: All values except those from the privileged group are under unprivileged groups.
The approach used in this princess is a simple test to compare the percentage of favorable results for the privileged and unprivileged groups, subtracting the former percentage from the latter.
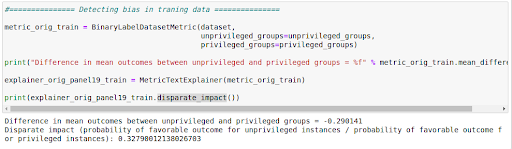
Figure 1.4 Bias detection
A negative value indicates less favorable outcomes for the unprivileged groups, which is implemented in the method called mean_difference on the BinaryLabelDatasetMetric class. The code shown in Figure 1.4 performs this check and displays the output, showing that the difference is -0.169905.
Moreover, the probability of a favorable outcome for unprivileged instances by privileged instances is approximately 0.33, which should be 1.
Bias mitigation
The previous step showed that the privileged group got 29% more positive outcomes in the dataset. Since it is not desirable, there is a need to mitigate the bias in the dataset.
An approach used here is called preprocessing mitigation because it happens before creating the model.
AIF360 supports several preprocessing mitigation algorithms such as Optimized Preprocessing, Disparate Impact Remover, Reweighing, etc. But here, it chooses the Reweighing class in the aif360.algorithms. They are preprocessing packages. This algorithm will transform the dataset to have more equity in positive outcomes on the protected attribute for the privileged and unprivileged groups.
Checking data after bias mitigation
Now, after transforming the dataset, it will check its effectiveness in removing bias. Once again, it uses the function mean_difference in the BinaryLabelDatasetMetric class.
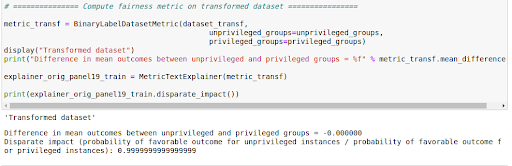
Figure 1.5 Bias detection after mitigation
From Figure 1.5, it is clear that the mitigation step was very effective; the difference in mean outcomes is now 0.0. So it went from a 29% advantage for the privileged group to equality in terms of the mean result. The probability of a favorable outcome for unprivileged instances by privileged instances is 0.99(near 1).
Conclusion
Chatbots and cobots are digital tools that base their operation on artificial intelligence, through which it is possible to simulate conversations with a person and automate other processes. Ethical AI focuses on the social impact of AI systems and their perceived fairness. Akira AI is a data intelligence platform that provides intelligence using analysis and learning by processing data from various sources to treat every individually fairly
Definitions, Acronyms, and Abbreviations
| Term | Meaning |
| AI | Artificial Intelligence |
| ML/DL | Machine Learning/Deep Learning |
| EDA | Exploratory Data Analysis |
- Read our blog on the latest technology here https://www.xenonstack.com/blog
- Begin Your Journey with us, click here to explore opportunities https://xenonstack.jobs/