

Guest Author: Debmalya Biswas, Philip Morris International/Nanoscope AI – Originally posted on Towardsdatascience.com
This is an extended article accompanying the presentation on “Open Source Enterprise AI/ML Governance” at Linux Foundation’s Open Compliance Summit, Dec 2020 (link) (pptx)
Abstract. With the growing adoption of Open Source based AI/ML systems in enterprises, there is a need to ensure that AI/ML applications are responsibly trained and deployed. This effort is complicated by different governmental organizations and regulatory bodies releasing their own guidelines and policies with little to no agreement on the definition of terms, e.g., there are 20+ definitions of ‘fairness’. In this article, we will provide an overview explaining the key components of this ecosystem: Data, Models, Software, Ethics and Vendor Management. We will outline the relevant regulations such that Compliance and Legal teams are better prepared to establish a comprehensive AI Governance framework. Along the way, we will also highlight some of the technical solutions available today that can be used to automate these requirements.
1. Enterprise AI
For the last 4–5 years, we have been working hard towards implementing various Artificial Intelligence/Machine Learning (AI/ML) use-cases at our enterprises. We have been focusing on building the most performant models, and now that we have a few of them in production; it is time to move beyond model precision to a more holistic AI Governance framework that ensures that our AI adoption is in line with organizational strategy, principles and policies.
The interesting aspect of such enterprises, even for mid-sized ones, is that AI/ML use-cases are pervasive. The enterprise use-cases can be broadly categorized based on the three core technical capabilities enabling them: Natural Language Processing (NLP), Computer Vision and Predictive Analytics (Fig. 1).
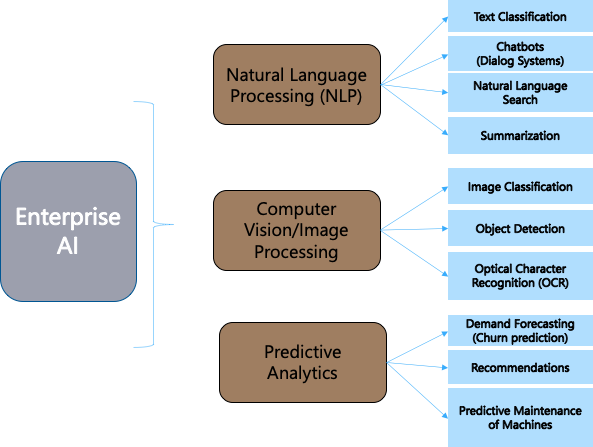
Their pervasiveness also implies that they get implemented and deployed via a diverse mix of approaches in the enterprise. We can broadly categorize them into three categories (Fig. 2):
- Models developed and trained from scratch, based on Open-Source AI/ML frameworks, e.g., scikit, TensorFlow, PyTorch. Transfer Learning may have been used. The point here is that we have full source code and data visibility in this scenario. The recently established Linux Foundation AI & Data Community (link) plays an important role in supporting and driving this thriving ecosystem of AI/Data related Open Source projects.
- Custom AI/ML applications developed by invoking ML APIs (e.g., NLP, Computer Vision, Recommenders) provided by Cloud providers, e.g., AWS, Microsoft Azure, Google Cloud, IBM Bluemix. The Cloud ML APIs can be considered as black box ML models, where we have zero visibility over the training data and underlying AI/ML algorithms. We however do retain visibility over the application logic.
- Finally, we consider the “intelligent” functionality embedded within ERP/CRM application suites, basically those provided by SAP, Salesforce, Oracle, etc. We have very little control or visibility in such scenarios, primarily acting as users of a Software-as-a-Service (SaaS) application - restricted to vendor specific development tools.

Needless to say, a mix of the three modes is also possible. And, in all three cases, the level of visibility/control varies depending on whether the implementation was performed by an internal team or an outsourced partner (service integrator). So, the first task from an enterprise governance point of view is to create an inventory of all AI/ML deployments – capturing at least the following details:
Use-case | Training/Source data characteristics | Model type (algorithm) |
Business function regulatory requirements | Deployment region
2. Ethical AI
“Ethical AI, also known as Responsible (or Trustworthy) AI, is the practice of using AI with good intention to empower employees and businesses, and fairly impact customers and society. Ethical AI enables companies to engender trust and scale AI with confidence.” [1]
Failing to operationalize Ethical AI can not only expose enterprises to reputational, regulatory, and legal risks; but also lead to wasted resources, inefficiencies in product development, and even an inability to use data to train AI models. [2]
There has been a recent trend towards ensuring that AI/ML applications are responsibly trained and deployed, in line with the enterprise strategy and policies. This is of course good news, but it has been complicated by different governmental organizations and regulatory bodies releasing their own guidelines and policies; with little to no agreement or standardization on the definition of terms, e.g., there are 20+ definitions of ‘fairness’ [3]. A recent survey [4] of AI Ethics guidelines of almost 84 documents around the world summarized “that no single ethical principle was common to all of the 84 documents on ethical AI we reviewed”.
- EU Ethics guidelines for Trustworthy AI (link)
- UK Guidance on the AI auditing framework (link)
- Singapore Model AI Governance Framework (link)
Software companies (e.g., Google, Microsoft, IBM) and the large consultancies (e.g., Accenture, Deloitte) have also jumped on the bandwagon, publishing their own AI Code of Ethics cookbooks.
- AI at Google: our principles (link)
- Microsoft AI Principals (link)
- IBM Trusted AI for Business (link)
- Accenture Responsible AI: A Framework for Building Trust in Your AI Solutions (link)
In general, they follow a similar storyline by first outlining their purpose, core principles, and then describing what they will (and will not) pursue — mostly focusing on social benefits, fairness, accountability, user rights/data privacy.
At this stage, they all seem like public relations exercises, with very little details on how to apply those high-level principles, across AI use-cases at scale.
In the context of the above discussion, we now turn our focus back on the top four AI/ML Principles that we need to start applying (or at least start thinking about) at enterprises — ideally, as part of a comprehensive AI Governance Framework. The fifth aspect would be ‘Data Privacy’ which has already received sufficient coverage and there seem to be mature practices in place at enterprises to address those concerns.
2.1 Explainability
Explainable AI is an umbrella term for a range of tools, algorithms and methods, which accompany AI model predictions with explanations. Explainability and transparency of AI models clearly ranks high among the list of ‘non-functional’ AI features to be considered first by enterprises. For example, this implies having to explain why an ML model profiled a user to be in a specific segment - which led him/her to receiving an advertisement. This aspect is also covered under the ‘Right to Explainability’ in most regulations, e.g., the below paragraph is quoted from the Singapore AI Governance Framework:
“It should be noted that technical explainability may not always be enlightening, especially to the man in the street. Implicit explanations of how the AI models’ algorithms function may be more useful than explicit descriptions of the models’ logic. For example, providing an individual with counterfactuals (such as “you would have been approved if your average debt was 15% lower” or “these are users with similar profiles to yours that received a different decision”) can be a powerful type of explanation that organisations could consider.”
The EU GDPR also covers the ‘Right to Explainability’ — refer to the below articles:
- Limits to decision making based solely on automated processing and profiling (Art. 22)
- Right to be provided with meaningful information about the logic involved in the decision (Art. 13, 15)
Note that GDPR does not mandate the ‘Right to Explainability’, rather it mandates the ‘Right to Information’. GDPR does allow the possibility of completely automated decision making as long as personal data is not involved, and the goal is not to evaluate the personality of a user — human intervention is needed in such scenarios.
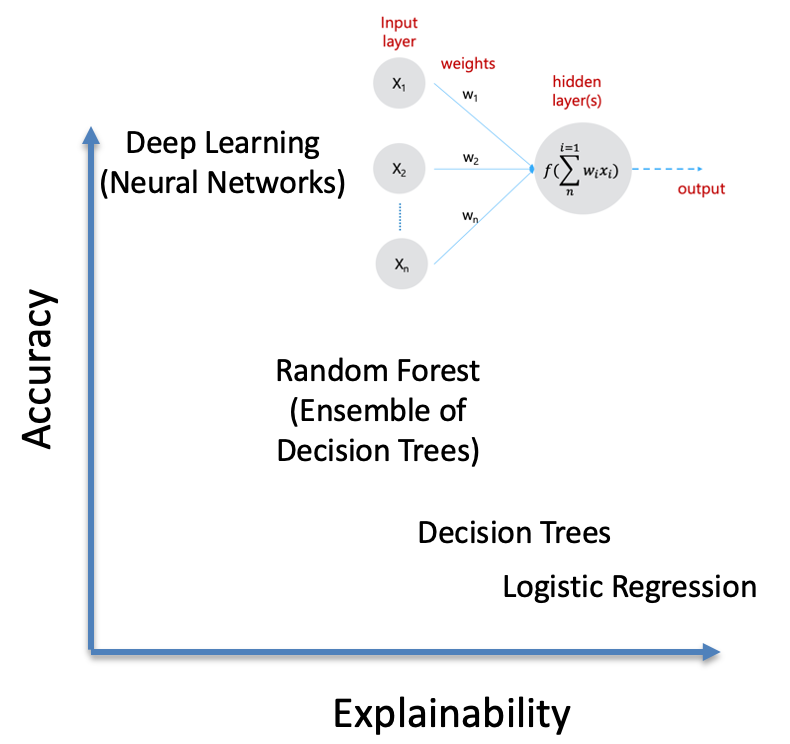
AI/ML practitioners will know that having data and source code visibility is not the same as ‘explainability’. Machine (Deep) Learning algorithms vary in the level of accuracy and explainability that they can provide , and it is not surprising that often the two are inversely proportional.
For example (Fig. 3), fundamental ML algorithms, e.g., Logistic Regression, Decision Trees, provide better explainability as it is possible to trace the independent variable weights and coefficients, and the various paths from nodes to leaves in a tree. One can notice ‘explainability’ becoming more difficult as we move to Random Forests, which are basically an ensemble of Decision Trees. At the end of the spectrum are Neural Networks, which have shown human-level accuracy. It is very difficult to correlate the impact of a (hyper)parameter assigned to a layer of the neural network, to the final decision in a deep (multi-layer) neural network. This is also the reason why optimizing a neural network currently remains a very ad-hoc and manual process — often based on the Data Scientist’s intuition [5].
It is also important to understand that an ‘explanation’ can mean different things for different users.
“the important thing is to explain the right thing to the right person in the right way at the right time” [6]
The right level of explanation abstraction (Fig. 4) depends on the goal, domain knowledge and complexity comprehension capabilities of the subjects. It is fair to say that most explainability frameworks today are targeted towards the AI/ML Developer.

Improving model explainability is an active area of research within the AI/ML Community, and there has been significant progress in model agnostic explainability frameworks (Fig. 5). As the name suggests, these frameworks separate explainability from the model, by trying to correlate the model predictions to the training data, without requiring any knowledge of the model internals.
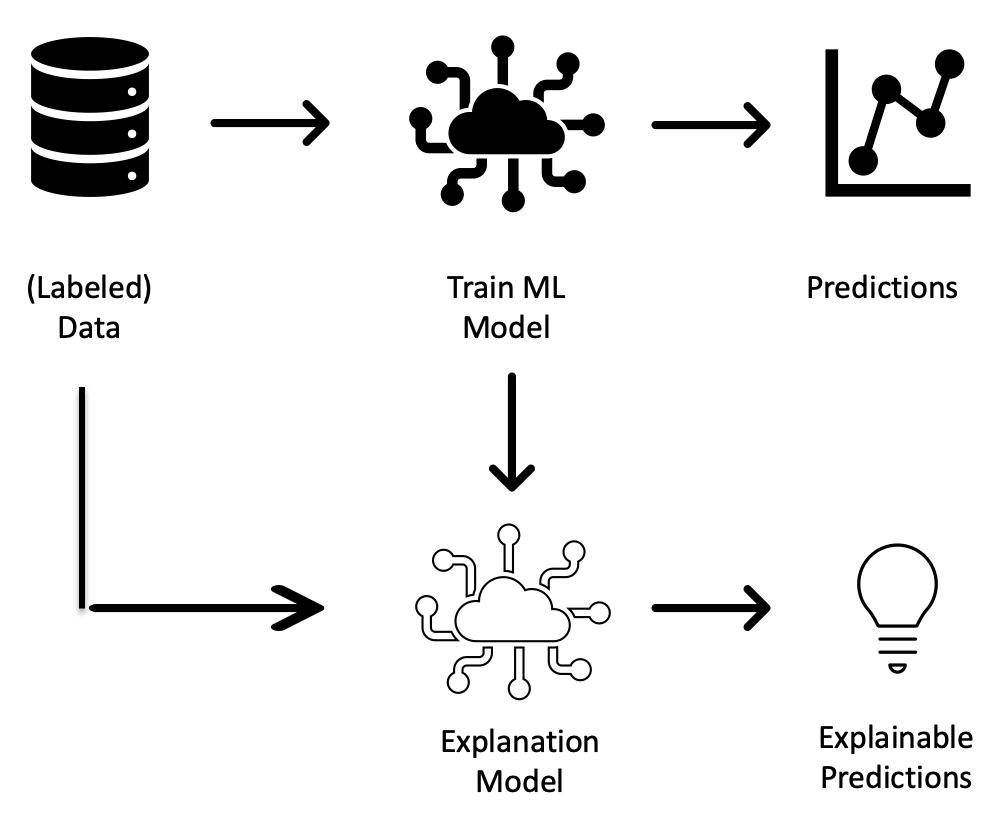
One of the most widely adopted model agnostic explainability frameworks is Local Interpretable Model-Agnostic Explanations (LIME). LIME is “a novel explanation technique that explains the predictions of any classifier in an interpretable and faithful manner by learning an interpretable model locally around the prediction.” LIME provides easy to understand (approximate) explanations of a prediction by training an explainability model based on samples around a prediction. It then weighs them based on their proximity to the original prediction. The approximate nature of the explainability model might limit its usage for compliance needs.
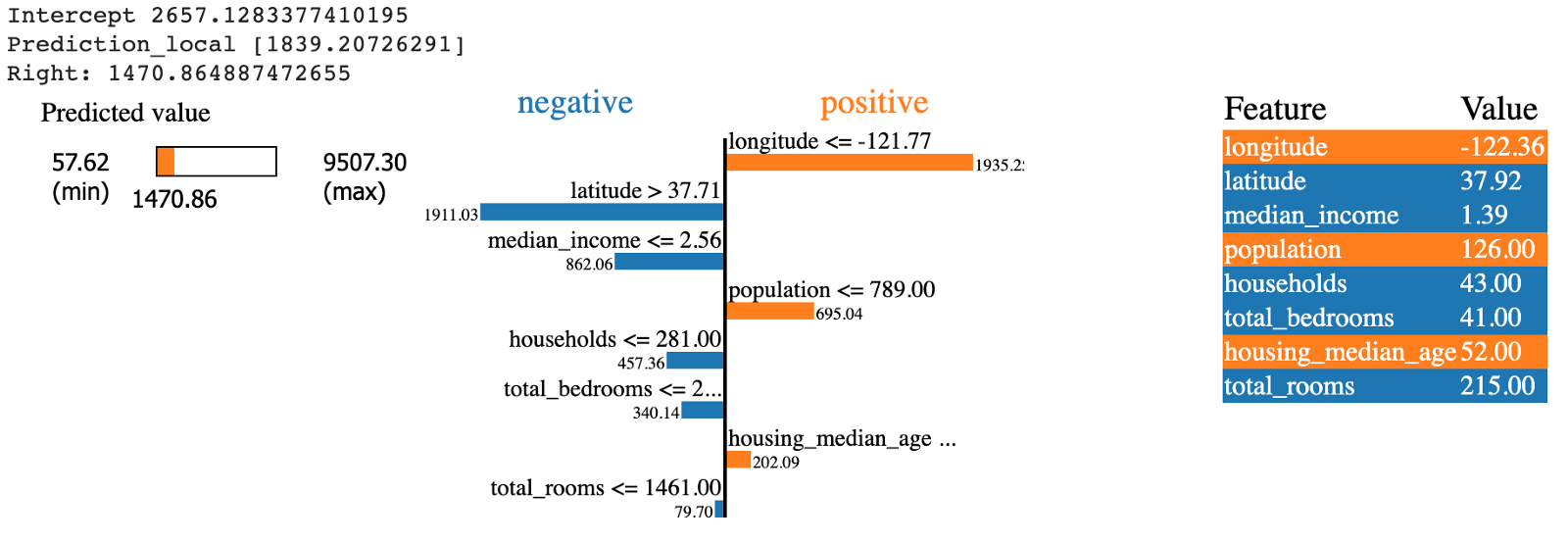
For example, the snapshot below (Fig. 6) shows the LIME output of an Artificial Neural Network (ANN) trained on a subset of the California Housing Prices Dataset (link). It shows the important features, positively and negatively impacting the model’s predictions.
As mentioned, this is an active research area, and progress continues to be made with the release of more such (sometimes model-specific) explainability frameworks and tools, e.g., the recently released NLP Language Interpretability Tool by Google Research (link). In practice, for commercial systems, the current SOTA would be Facebook’s ‘Why you’re seeing this Post’ [7] – Fig. 7.
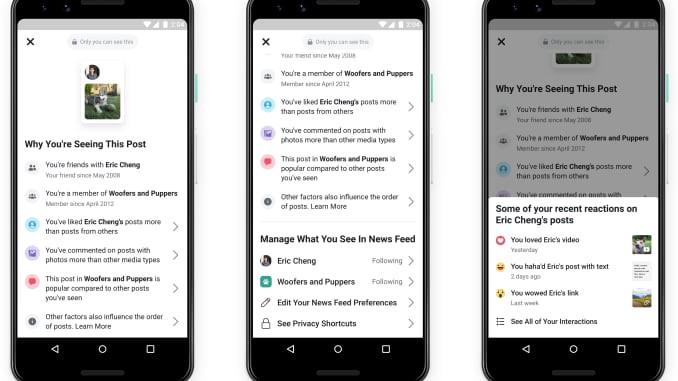
It includes information on how often they interact with that post’s author, medium (videos, photos or links); and the popularity of the post compared to others. The feature is an extension of their ‘Why am I seeing this ad?’ which includes information on how the user’s Facebook profile data matched details provided by an advertiser.
2.2 Bias and Fairness
[8] defines AI/ML Bias “as a phenomenon that occurs when an algorithm produces results that are systemically prejudiced due to erroneous assumptions in the machine learning process”.
Bias in AI/ML models is often unintentional; however, it has been observed far too frequently in deployed use-cases to be taken lightly. Google Photo labeling pictures of a black Haitian-American programmer as “gorilla”, to the more recent “White Barack Obama” images; are examples of ML models discriminating on gender, age, sexual orientation, etc. The unintentional nature of such biases will not prevent your enterprise from getting fined by regulatory bodies or facing public backlash on social media — leading to loss of business. Even without the above repercussions, it is just ethical that AI/ML models should behave in all fairness towards everyone, without any bias. However, defining ‘fairness’ is easier said than done. Does fairness mean, e.g., that the same proportion of male and female applicants get high risk assessment scores? Or that the same level of risk result in the same score regardless of gender? It’s impossible to fulfill both definitions at the same time [9].
Bias creeps into AI models, primarily due to the inherent bias already present in the training data. As such, the ‘data’ part of AI model development is key to addressing bias.
[10] provides a good classification of the different types of ‘bias’ — introduced at different stages of the AI/ML development lifecycle (Fig. 8):
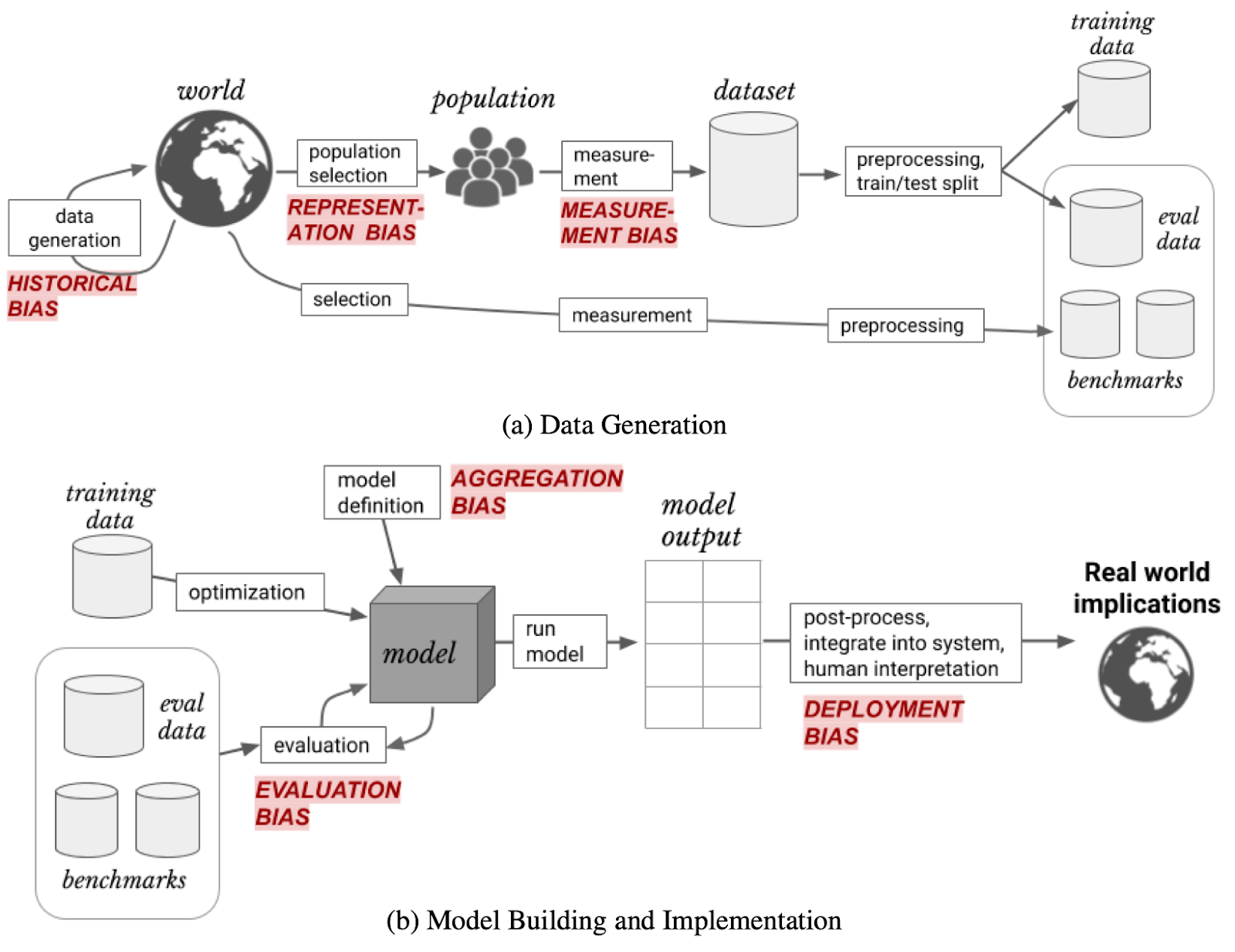
Focusing on the ‘training data’ related bias types,
- Historical Bias: arises due to historical inequality of human decisions captured in the training data
- Representation Bias: arises due to training data that is not representative of the actual population
- Measurement & Aggregation Bias: arises due to improper selection and combination of features.
A detailed analysis of the training data is needed to ensure that it is representative and uniformly distributed over the target population, with respect to the selected features. Explainability also plays an important role in detecting bias in AI/ML models.
In terms of tools, TensorFlow Fairness Indicators (link) is a good example of a library that enables easy computation of commonly identified fairness metrics.
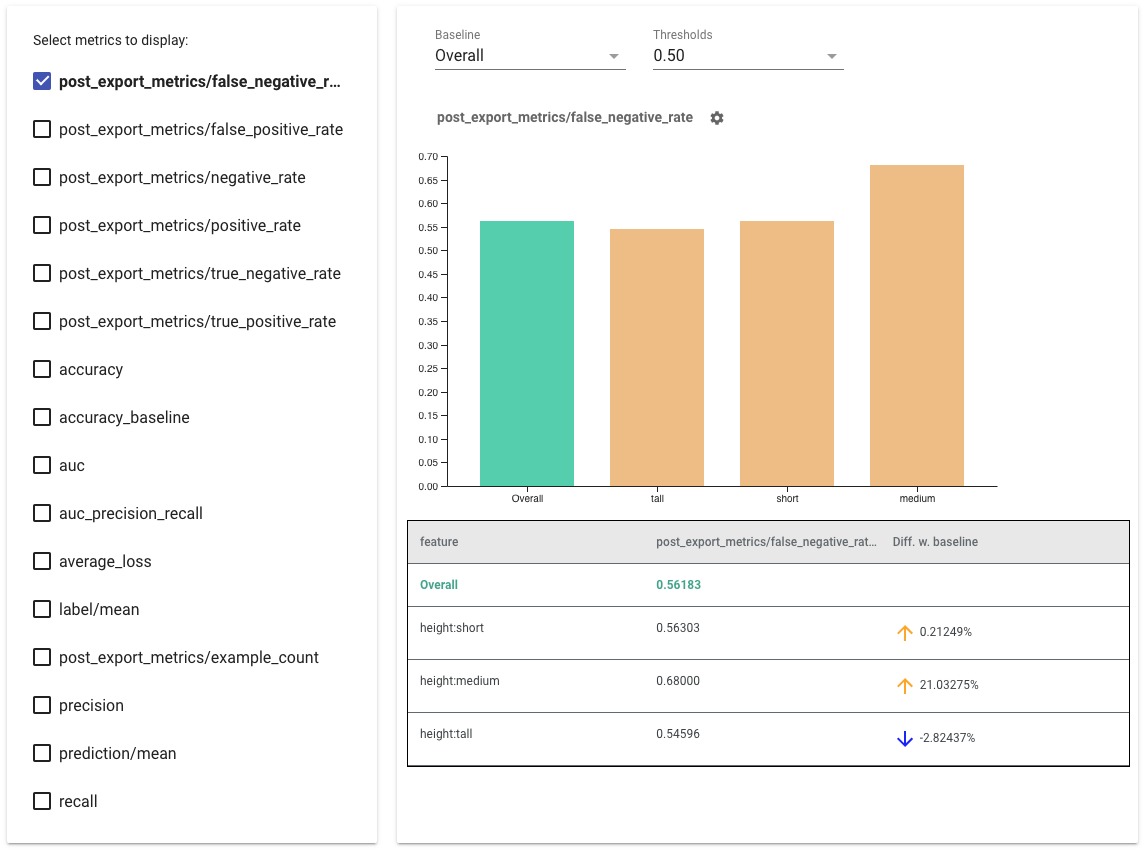
Here, it is important to mention that bias detection is not a one-time activity. Similar to monitoring model drift, we need to plan for bias detection to be performed on a continual basis. As new data comes in (including feedback loops), a model that is unbiased today can become biased tomorrow. For instance, this is what happened with Microsoft’s ‘teen girl’ AI Chatbot, which within hours of its deployment had learned to become a “a Hitler-loving sex robot”.
2.3 Reproducibility
Reproducibility is a basic principle of Ethical AI and it implies that “All AI/ML predictions must be reproducible.” If an outcome cannot be reproduced, it cannot be trusted. The combination of model version, (hyper-)parameter setting, training dataset features, etc. that contribute to a single prediction can make reproducibility challenging to implement in practice.
To make AI truly reproducible, we need to maintain the precise lineage and provenance of every ML prediction.
This is provided by a mix of MLOps and Data Governance practices. Facebook AI Research (FAIR) recently introduced the ML Code Completeness Checklist to enhance reproducibility and provide a collection of best practices and code repository assessments, allowing users to build upon previously published work [11]. While MLOps [12] seems to be in vogue, there is an inherent lack of principles/standardization on the Data side. A promising framework in this context is FAIR [13], which has started to get widespread adoption in Healthcare Research.
- Findable: Data should be easy to find for both humans and machines, which implies rich metadata and unique/persistent identifier.
- Accessible: Data can be accessed in a trusted fashion with authentication and authorization provisions.
- Interoperable: Shared ontology for knowledge representation, ensuring that the data can interoperate with multiple applications/workflows for analysis, storage, and processing.
- Reusable: Clear provenance/lineage specifications and usage licenses such that the data can be reused in different settings.
While FAIR is quite interesting from a Data Governance perspective, it remains to be seen how it gets adopted outside Healthcare Research. The Open Data licenses (e.g., Creative Commons) are very different from the more mature landscape of Open Source Software licenses, e.g. Apache, MIT [14].
There is a great risk that we will end up in another standardization/licensing mess, rather than a comprehensive framework to store, access and analyze both data and models (code) in a unified fashion.
2.4 Accountability
Similar to the debate on self-driving cars with respect to “who is responsible” if an accident happens? Is it the user, car manufacturer, insurance provider, or even the city municipality (due a problem with the road traffic signals)? The same debate applies in the case of AI models as well — who is accountable if something goes wrong?, e.g., as explained above in the case of a biased AI/ML model deployment.
Accountability is esp. important if the AI/ML model is developed and maintained by an outsourced partner/vendor.
Below we outline a few questions (in the form of a checklist) that needs to considered/clarified before signing the contract with your preferred partner:
- Liability: Given that we are engaging with a 3rd party, to what extent are they liable? This is tricky to negotiate and depends on the extent to which the AI system can operate independently. For example, in the case of a Chatbot, if the bot is allowed to provide only a limited output (e.g., respond to a consumer with only limited number of pre-approved responses), then the risk is likely to be a lot lower as compared to an open-ended bot that is free to respond. In addition:
What contractual promises should we negotiate (e.g., warranties, SLAs)?
What measures to we need to implement if something goes wrong (e.g., contingency planning)?
- Data ownership: Data is critical to AI/ML systems, as such negotiation of ownership issues around not only training data, but input data, output data, and other generated data is critical. For example, in the context of a consumer facing Chatbot [14]:
- Input data could be the questions asked by consumers whilst interacting with the bot.
- Output data could be the bot’s responses, i.e., the answers given to the consumers by the bot.
- Other generated data include the insights gathered as a result of our consumers use of the AI, e.g., the number of questions asked, types of questions asked, etc.
Also, if the vendor is generating the training data, basically bearing the cost for annotation; do we still want to own the training data?
- Confidentiality and IP/Non-Compete clauses: In addition to (training) data confidentiality, do we want to prevent the vendor from providing our competitors with access to the trained model, or at least any improvements to it — particularly if it is giving us a competitive advantage? With respect to IP, we are primarily interested in the IP of the source code – at an algorithmic level.
Who owns the rights of the underlying algorithm? Is it proprietary to a 3rd party? If yes, have we negotiated appropriate license rights, such that we can use the AI system in the manner that we want?
When we engage with vendors to develop an AI system, is patent protection possible, and if so, who has the right to file for the patent?
3. Conclusion
To conclude, we have highlighted four key aspects of AI/ML model development that we need to start addressing today — as part of a holistic AI Governance Framework.
As with everything in life, esp. in IT, there is no clear black and white and a blanket AI policy mandating the usage of only explainable AI/ML models is not optimal — implies missing out on what non-explainable algorithms can provide.
Depending on the use-case and geographic regulations, there is always scope for negotiation. The regulations related to different use-cases (e.g., profiling), are different in different geographies. In terms of bias and explainability as well, we have the full spectrum from ‘fully explainable’ to ‘partially explainable, but auditable’ to ‘fully opaque, but with very high accuracy’. Given this, there is a need to form a knowledgeable and interdisciplinary team (consisting of at least IT, Legal, Procurement, Business representatives), often referred to as the AI Ethics Committee — that can take such decisions in a consistent fashion, in-line with the company values and strategy.
References
- R. E-Porter. Beyond the promise: implementing Ethical AI (link)
- R. Blackman. A Practical Guide to Building Ethical AI (link)
- S. Verma, J. Rubin. Fairness definitions explained (link)
- A. Jobin, M. Ienca, E. Vayena. The global landscape of AI Ethics Guidelines (link)
- D. Biswas. Is AutoML ready for Business?. Medium, 2020 (link)
- N. Xie, et. al. Explainable Deep Learning: A Field Guide for the Uninitiated (link)
- CNBC. Facebook has a new tool that explains why you’re seeing certain posts on your News Feed (link)
- SearchEnterprise AI. Machine Learning bias (AI bias) (link)
- K. Hao. This is how AI Bias really happens — and why it’s so Hard to Fix (link)
- H. Suresh, J. V. Guttag. A Framework for Understanding Unintended Consequences of Machine Learning (link)
- Facebook AI Research. New code completeness checklist and reproducibility updates (link)
- Google Cloud. MLOps: Continuous Delivery and Automation Pipelines in Machine Learning (link)
- GO Fair. The FAIR Guiding Principles for Scientific Data Management and Stewardship (link)
- D. Biswas. Managing Open Source Software in the Enterprise. Medium, 2020 (link)
- D. Biswas. Privacy Preserving Chatbot Conversations. In proceeding of the 3rd NeurIPS Workshop on Privacy-preserving Machine Learning (PPML), 2020 (paper)
- Gartner. Improve the Machine Learning Trust Equation by Using Explainable AI Frameworks (link)
- Google. Closing the AI Accountability Gap: Defining an End-to-End Framework for Internal Algorithmic Auditing (link)
- Forbes. ML Integrity: Four Production Pillars For Trustworthy AI (link)
- Forrester. Five AI Principles To Put In Practice (link)
- Deloitte. AI Ethics: A Business Imperative for Boards and C-suites (link)
LF AI & Data Resources
- Learn about membership opportunities
- Explore the interactive landscape
- Check out our technical projects
- Join us at upcoming events
- Read the latest announcements on the blog
- Subscribe to the mailing lists
- Follow us on Twitter or LinkedIn
- Access other resources on LF AI & Data’s GitHub or Wiki