


*Note: This blog post was originally published on the AWS Machine Learning Blog, LF AI & Data reposted it here to amplify its reach.
by Abhi Shivaditya, Dhawalkumar Patel, James Park, and Rupinder Grewal, Saurabh Trikande
ONNX (Open Neural Network Exchange) is an open source standard for representing deep learning models widely supported by many providers. ONNX provides tools for optimizing and quantizing models to reduce the memory and compute needed to run machine learning (ML) models. One of the biggest benefits of ONNX is that it provides a standardized format for representing and exchanging ML models between different frameworks and tools. This allows developers to train their models in one framework and deploy them in another without the need for extensive model conversion or retraining. For these reasons, ONNX has gained significant importance in the ML community.
In this post, we showcase how to deploy ONNX-based models for multi-model endpoints (MMEs) that use GPUs. This is a continuation of the post Run multiple deep learning models on GPU with Amazon SageMaker multi-model endpoints, where we showed how to deploy PyTorch and TensorRT versions of ResNet50 models on Nvidia’s Triton Inference server. In this post, we use the same ResNet50 model in ONNX format along with an additional natural language processing (NLP) example model in ONNX format to show how it can be deployed on Triton. Furthermore, we benchmark the ResNet50 model and see the performance benefits that ONNX provides when compared to PyTorch and TensorRT versions of the same model, using the same input.

ONNX Runtime
ONNX Runtime is a runtime engine for ML inference designed to optimize the performance of models across multiple hardware platforms, including CPUs and GPUs. It allows the use of ML frameworks like PyTorch and TensorFlow. It facilitates performance tuning to run models cost-efficiently on the target hardware and has support for features like quantization and hardware acceleration, making it one of the ideal choices for deploying efficient, high-performance ML applications. For examples of how ONNX models can be optimized for Nvidia GPUs with TensorRT, refer to TensorRT Optimization (ORT-TRT) and ONNX Runtime with TensorRT optimization.
The Amazon SageMaker Triton container flow is depicted in the following diagram.
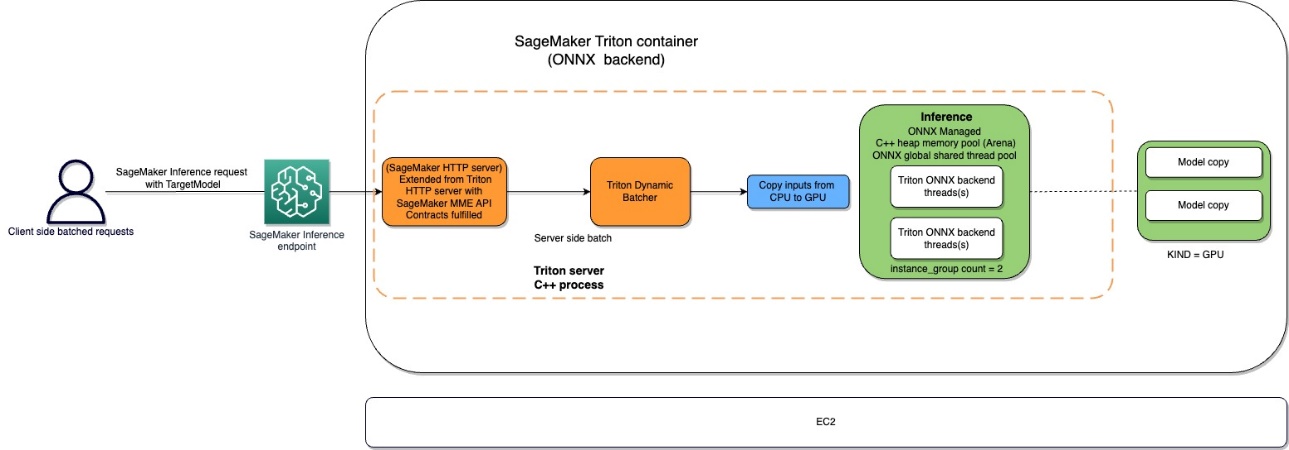
Users can send an HTTPS request with the input payload for real-time inference behind a SageMaker endpoint. The user can specify a TargetModel header that contains the name of the model that the request in question is destined to invoke. Internally, the SageMaker Triton container implements an HTTP server with the same contracts as mentioned in How Containers Serve Requests. It has support for dynamic batching and supports all the backends that Triton provides. Based on the configuration, the ONNX runtime is invoked and the request is processed on CPU or GPU as predefined in the model configuration provided by the user.
Solution overview
To use the ONNX backend, complete the following steps:
- Compile the model to ONNX format.
- Configure the model.
- Create the SageMaker endpoint.
Prerequisites
Ensure that you have access to an AWS account with sufficient AWS Identity and Access Management IAM permissions to create a notebook, access an Amazon Simple Storage Service (Amazon S3) bucket, and deploy models to SageMaker endpoints. See Create execution role for more information.
Compile the model to ONNX format
The transformers library provides for convenient method to compile the PyTorch model to ONNX format. The following code achieves the transformations for the NLP model:
Exporting models (either PyTorch or TensorFlow) is easily achieved through the conversion tool provided as part of the Hugging Face transformers repository.
The following is what happens under the hood:
- Allocate the model from transformers (PyTorch or TensorFlow).
- Forward dummy inputs through the model. This way, ONNX can record the set of operations run.
- The transformers inherently take care of dynamic axes when exporting the model.
- Save the graph along with the network parameters.
A similar mechanism is followed for the computer vision use case from the torchvision model zoo:
Configure the model
In this section, we configure the computer vision and NLP model. We show how to create a ResNet50 and RoBERTA large model that has been pre-trained for deployment on a SageMaker MME by utilizing Triton Inference Server model configurations. The ResNet50 notebook is available on GitHub. The RoBERTA notebook is also available on GitHub. For ResNet50, we use the Docker approach to create an environment that already has all the dependencies required to build our ONNX model and generate the model artifacts needed for this exercise. This approach makes it much easier to share dependencies and create the exact environment that is needed to accomplish this task.
The first step is to create the ONNX model package per the directory structure specified in ONNX Models. Our aim is to use the minimal model repository for a ONNX model contained in a single file as follows:
Next, we create the model configuration file that describes the inputs, outputs, and backend configurations for the Triton Server to pick up and invoke the appropriate kernels for ONNX. This file is known as config.pbtxt and is shown in the following code for the RoBERTA use case. Note that the BATCH dimension is omitted from the config.pbtxt. However, when sending the data to the model, we include the batch dimension. The following code also shows how you can add this feature with model configuration files to set dynamic batching with a preferred batch size of 5 for the actual inference. With the current settings, the model instance is invoked instantly when the preferred batch size of 5 is met or the delay time of 100 microseconds has elapsed since the first request reached the dynamic batcher.
The following is the similar configuration file for the computer vision use case:
Create the SageMaker endpoint
We use the Boto3 APIs to create the SageMaker endpoint. For this post, we show the steps for the RoBERTA notebook, but these are common steps and will be the same for the ResNet50 model as well.
Create a SageMaker model
We now create a SageMaker model. We use the Amazon Elastic Container Registry (Amazon ECR) image and the model artifact from the previous step to create the SageMaker model.
Create the container
To create the container, we pull the appropriate image from Amazon ECR for Triton Server. SageMaker allows us to customize and inject various environment variables. Some of the key features are the ability to set the BATCH_SIZE; we can set this per model in the config.pbtxt file, or we can define a default value here. For models that can benefit from larger shared memory size, we can set those values under SHM variables. To enable logging, set the log verbose level to true. We use the following code to create the model to use in our endpoint:
Create a SageMaker endpoint
You can use any instances with multiple GPUs for testing. In this post, we use a g4dn.4xlarge instance. We don’t set the VolumeSizeInGB parameters because this instance comes with local instance storage. The VolumeSizeInGB parameter is applicable to GPU instances supporting the Amazon Elastic Block Store (Amazon EBS) volume attachment. We can leave the model download timeout and container startup health check at the default values. For more details, refer to CreateEndpointConfig.
Lastly, we create a SageMaker endpoint:
Invoke the model endpoint
This is a generative model, so we pass in the input_ids and attention_mask to the model as part of the payload. The following code shows how to create the tensors:
We now create the appropriate payload by ensuring the data type matches what we configured in the config.pbtxt. This also give us the tensors with the batch dimension included, which is what Triton expects. We use the JSON format to invoke the model. Triton also provides a native binary invocation method for the model.
Note the TargetModel parameter in the preceding code. We send the name of the model to be invoked as a request header because this is a multi-model endpoint, therefore we can invoke multiple models at runtime on an already deployed inference endpoint by changing this parameter. This shows the power of multi-model endpoints!
To output the response, we can use the following code:
ONNX for performance tuning
The ONNX backend uses C++ arena memory allocation. Arena allocation is a C++-only feature that helps you optimize your memory usage and improve performance. Memory allocation and deallocation constitutes a significant fraction of CPU time spent in protocol buffers code. By default, new object creation performs heap allocations for each object, each of its sub-objects, and several field types, such as strings. These allocations occur in bulk when parsing a message and when building new messages in memory, and associated deallocations happen when messages and their sub-object trees are freed.
Arena-based allocation has been designed to reduce this performance cost. With arena allocation, new objects are allocated out of a large piece of pre-allocated memory called the arena. Objects can all be freed at once by discarding the entire arena, ideally without running destructors of any contained object (though an arena can still maintain a destructor list when required). This makes object allocation faster by reducing it to a simple pointer increment, and makes deallocation almost free. Arena allocation also provides greater cache efficiency: when messages are parsed, they are more likely to be allocated in continuous memory, which makes traversing messages more likely to hit hot cache lines. The downside of arena-based allocation is the C++ heap memory will be over-allocated and stay allocated even after the objects are deallocated. This might lead to out of memory or high CPU memory usage. To achieve the best of both worlds, we use the following configurations provided by Triton and ONNX:
- arena_extend_strategy – This parameter refers to the strategy used to grow the memory arena with regards to the size of the model. We recommend setting the value to 1 (=
kSameAsRequested), which is not a default value. The reasoning is as follows: the drawback of the default arena extend strategy (kNextPowerOfTwo) is that it might allocate more memory than needed, which could be a waste. As the name suggests,kNextPowerOfTwo(the default) extends the arena by a power of 2, whereaskSameAsRequestedextends by a size that is the same as the allocation request each time.kSameAsRequestedis suited for advanced configurations where you know the expected memory usage in advance. In our testing, because we know the size of models is a constant value, we can safely choosekSameAsRequested. - gpu_mem_limit – We set the value to the CUDA memory limit. To use all possible memory, pass in the maximum
size_t. It defaults toSIZE_MAXif nothing is specified. We recommend keeping it as default. - enable_cpu_mem_arena – This enables the memory arena on CPU. The arena may pre-allocate memory for future usage. Set this option to
falseif you don’t want it. The default isTrue. If you disable the arena, heap memory allocation will take time, so inference latency will increase. In our testing, we left it as default. - enable_mem_pattern – This parameter refers to the internal memory allocation strategy based on input shapes. If the shapes are constant, we can enable this parameter to generate a memory pattern for the future and save some allocation time, making it faster. Use 1 to enable the memory pattern and 0 to disable. It’s recommended to set this to 1 when the input features are expected to be the same. The default value is 1.
- do_copy_in_default_stream – In the context of the CUDA execution provider in ONNX, a compute stream is a sequence of CUDA operations that are run asynchronously on the GPU. The ONNX runtime schedules operations in different streams based on their dependencies, which helps minimize the idle time of the GPU and achieve better performance. We recommend using the default setting of 1 for using the same stream for copying and compute; however, you can use 0 for using separate streams for copying and compute, which might result in the device pipelining the two activities. In our testing of the ResNet50 model, we used both 0 and 1 but couldn’t find any appreciable difference between the two in terms of performance and memory consumption of the GPU device.
- Graph optimization – The ONNX backend for Triton supports several parameters that help fine-tune the model size as well as runtime performance of the deployed model. When the model is converted to the ONNX representation (the first box in the following diagram at the IR stage), the ONNX runtime provides graph optimizations at three levels: basic, extended, and layout optimizations. You can activate all levels of graph optimizations by adding the following parameters in the model configuration file:
- cudnn_conv_algo_search – Because we’re using CUDA-based Nvidia GPUs in our testing, for our computer vision use case with the ResNet50 model, we can use the CUDA execution provider-based optimization at the fourth layer in the following diagram with the
cudnn_conv_algo_searchparameter. The default option is exhaustive (0), but when we changed this configuration to1 – HEURISTIC, we saw the model latency in steady state reduce to 160 milliseconds. The reason this happens is because the ONNX runtime invokes the lighter weight cudnnGetConvolutionForwardAlgorithm_v7 forward pass and therefore reduces latency with adequate performance. - Run mode – The next step is selecting the correct execution_mode at layer 5 in the following diagram. This parameter controls whether you want to run operators in your graph sequentially or in parallel. Usually when the model has many branches, setting this option to
ExecutionMode.ORT_PARALLEL(1) will give you better performance. In the scenario where your model has many branches in its graph, setting the run mode to parallel will help with better performance. The default mode is sequential, so you can enable this to suit your needs.
For a deeper understanding of the opportunities for performance tuning in ONNX, refer to the following figure.

Benchmark numbers and performance tuning
By turning on the graph optimizations, cudnn_conv_algo_search, and parallel run mode parameters in our testing of the ResNet50 model, we saw the cold start time of the ONNX model graph reduce from 4.4 seconds to 1.61 seconds. An example of a complete model configuration file is provided in the ONNX configuration section of the following notebook.
The testing benchmark results are as follows:
- PyTorch – 176 milliseconds, cold start 6 seconds
- TensorRT – 174 milliseconds, cold start 4.5 seconds
- ONNX – 168 milliseconds, cold start 4.4 seconds
The following graphs visualize these metrics.



Furthermore, in our testing of computer vision use cases, consider sending the request payload in binary format using the HTTP client provided by Triton because it significantly improves model invoke latency.
Other parameters that SageMaker exposes for ONNX on Triton are as follows:
- Dynamic batching – Dynamic batching is a feature of Triton that allows inference requests to be combined by the server, so that a batch is created dynamically. Creating a batch of requests typically results in increased throughput. The dynamic batcher should be used for stateless models. The dynamically created batches are distributed to all model instances configured for the model.
- Maximum batch size – The
max_batch_sizeproperty indicates the maximum batch size that the model supports for the types of batching that can be exploited by Triton. If the model’s batch dimension is the first dimension, and all inputs and outputs to the model have this batch dimension, then Triton can use its dynamic batcher or sequence batcher to automatically use batching with the model. In this case,max_batch_sizeshould be set to a value greater than or equal to 1, which indicates the maximum batch size that Triton should use with the model. - Default max batch size – The default-max-batch-size value is used for
max_batch_sizeduring autocomplete when no other value is found. Theonnxruntimebackend will set themax_batch_sizeof the model to this default value if autocomplete has determined the model is capable of batching requests andmax_batch_sizeis 0 in the model configuration ormax_batch_sizeis omitted from the model configuration. Ifmax_batch_sizeis more than 1 and no scheduler is provided, the dynamic batch scheduler will be used. The default max batch size is 4.
Clean up
Ensure that you delete the model, model configuration, and model endpoint after running the notebook. The steps to do this are provided at the end of the sample notebook in the GitHub repo.
Conclusion
In this post, we dove deep into the ONNX backend that Triton Inference Server supports on SageMaker. This backend provides for GPU acceleration of your ONNX models. There are many options to consider to get the best performance for inference, such as batch sizes, data input formats, and other factors that can be tuned to meet your needs. SageMaker allows you to use this capability using single-model and multi-model endpoints. MMEs allow a better balance of performance and cost savings. To get started with MME support for GPU, see Host multiple models in one container behind one endpoint.
We invite you to try Triton Inference Server containers in SageMaker, and share your feedback and questions in the comments.