


Author: Nishant Satya Lakshmikanth, Engineering Leader, LinkedIn Corporation
Introduction
In Part 1, we explored how Large Language Models (LLMs) are expanding the scope of recommender systems—from passive prediction tools to conversational, context-aware agents. But the real shift begins when these conceptual promises are translated into architecture and code. As organizations move beyond experimentation, the question is no longer whether LLMs can improve recommendations—but how to integrate them effectively into high-throughput, low-latency systems while preserving accuracy, fairness, and scalability.
This part serves as a technical blueprint for that journey, framed within the open, community-driven perspective of LF AI & Data’s GenAI Commons. We examine the end-to-end architecture of LLM-powered recommender systems, including multi-modal representation strategies and knowledge-aware reasoning flows. We then dive into practical implementation methods—from fine-tuning and parameter-efficient learning (like LoRA) to prompt-based and in-context learning (ICL). Each method balances flexibility, resource cost, and explainability, offering trade-offs based on real-world deployment scenarios.
By the end of this section, you’ll see how LLMs can be embedded not just as a final scoring layer, but throughout the recommendation pipeline—as representation generators, reasoning engines, rerankers, or evaluators. This deep dive equips engineers and researchers with the foundational patterns and modular techniques required to architect LLM-infused systems that are powerful, interpretable, and production-ready.
Overall Pipeline
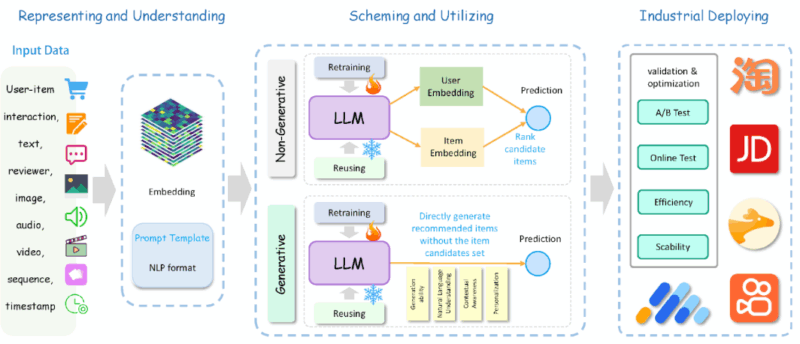
Figure-1: Overall Pipeline (source)
Representation
Uni-modality recommendations primarily rely on a single type of data, often represented through graph-based methods that model user-item interactions. These graphs capture structural relationships, helping to predict user preferences by identifying patterns in interactions. In some cases, textual information is integrated into the graph structure, enriching semantic understanding and improving recommendation quality. This approach is particularly effective for sequential and session-based recommendations, where real-time adaptability is required to reflect evolving user behaviors.
Multi-modality recommendations, on the other hand, leverage a diverse range of data sources, including text, images, audio, video, and metadata. By integrating these varied inputs, recommender systems overcome challenges such as sparse feedback and low-quality side information. Advanced techniques like graph augmentation and textual information integration enhance user-item interaction modeling, while multimodal large language models (MLLMs) enable the incorporation of complex real-time data, such as screenshots of user activities. This approach not only improves interpretability and robustness but also enhances the system’s adaptability across different domains and use cases.
Understanding
Large language model (LLM)-based recommender systems leverage external world knowledge and advanced reasoning capabilities to offer deeper insights into user preferences, item attributes, and behavioral patterns. These models not only integrate external knowledge but also enhance the ability to reason about user motivations and the broader social context in which interactions occur. This enables a more comprehensive understanding of why certain recommendations are made.
To enhance explainability, current methods can be categorized based on when the explanation is provided:
- Pre-recommendation explanations, which offer insights into the reasoning behind a suggestion before it is generated, improving user trust and decision-making.
- Post-recommendation explanations, which justify the recommendation after it is presented, helping users interpret and engage with the suggestions more effectively.
By improving both explanation and transparency, LLM-powered recommender systems not only enhance accuracy and personalization but also foster greater trust and interpretability, making them more user-centric and adaptable to diverse needs
Scheming and Utilizing
The rise of large language models (LLMs) has significantly reshaped recommender systems, driving new research into how best to integrate them.
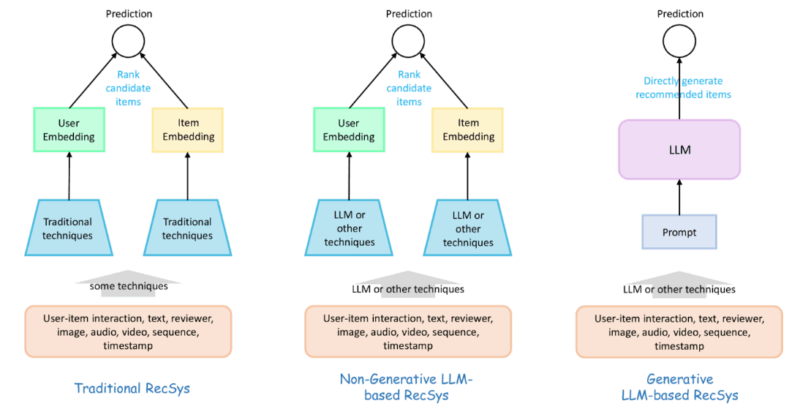
Figure-2: Recsys using LLM’s in different forms (source)
Broadly, recommendation approaches fall into three key categories:
Traditional Recommendation Approaches
These methods rely on collaborative filtering (analyzing past interactions between users and items) and content-based filtering (matching users with similar items based on attributes). Traditional models typically employ matrix factorization, gradient boosting, or deep learning for ranking and prediction. While effective, these approaches often struggle with cold-start problems, sparse data, and limited contextual understanding.
Non-Generative LLM-based Approaches
Non-Generative LLM-based recommendations leverage large language models (LLMs) to enhance traditional recommendation tasks without directly generating natural language outputs. Instead of producing recommendations in free-form text, these methods utilize LLMs to improve ranking, scoring, and feature extraction by embedding their deep understanding of natural language into the recommendation process.
Unlike generative approaches, non-generative methods integrate LLMs as enhancement layers within a multi-stage recommendation pipeline. This typically includes:
- Embedding Generation: LLMs create rich user and item embeddings that capture deeper semantic relationships. These embeddings can be stored in a vector database and used for nearest-neighbor search to retrieve the most relevant candidates efficiently.
- Feature Enrichment: LLMs extract meaningful semantic features from unstructured data (e.g., text descriptions, reviews, or metadata), which can be integrated into traditional machine learning-based ranking models.
- Ranking & Scoring: Instead of directly generating recommendations, LLMs refine ranking models by improving candidate selection and relevance scoring, ensuring better alignment with user preferences.
By embedding LLMs into specific stages of the recommendation process, non-generative methods enhance precision and personalization while maintaining the efficiency and interpretability of traditional recommendation frameworks
Generative LLM-based Approaches
Generative recommenders cast recommendation as NLG: the model produces items (or item IDs plus rationales) instead of scoring a fixed candidate set. This collapses multi-stage ranking into one generative step that fuses context, preferences, and history. To avoid bespoke pipelines, adopt community-standard schemas, prompt/eval packs, and safe-output contracts from LF AI & Data’s GenAI Commons, so prompts, guardrails, and outputs are portable across stacks.
In advanced deployments, models are fine-tuned on domain data and steered at inference with templated prompts to judge viewer–entity pairs. Retrieval-augmented context (profiles, catalogs, sessions) and policy checks shape responses; structured outputs (JSON/IDs) feed logging and A/Bs. The result is dynamic, personalized suggestions that remain auditable and reproducible across teams.
LLM-Based Recommender System Paradigms
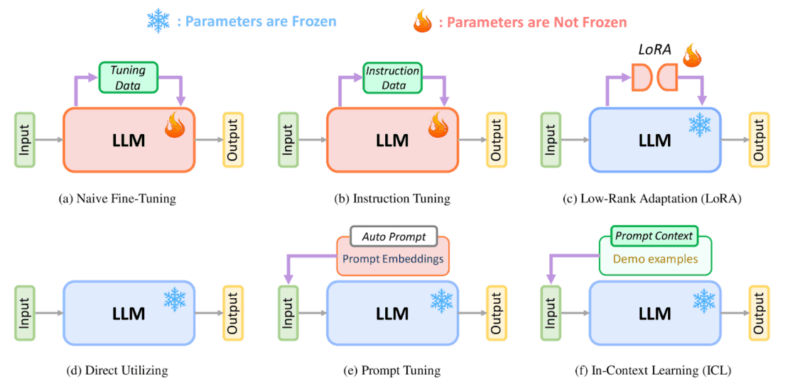
Figure-3: Using LLM and different techniques (source)
| Paradigm | Description | Case studies |
| Naive Fine-Tuning | Customizes models for specific recommendation tasks using domain-specific data | Boz et al (source) explores the impact of fine-tuning LLMs for recommendation tasks, demonstrating that fine-tuning not only improves task-specific performance but also enables models to acquire deeper domain knowledge. Their findings indicate that OpenAI’s GPT significantly outperforms Google’s PaLM 2 in recommendation settings, highlighting differences in how these models adapt to fine-tuning. This suggests that fine-tuning is not just about improving accuracy but also about selecting the right base model for domain-specific adaptation.
Wang et al (source) investigates how fine-tuning both context-aware embeddings and the recommendation LLM itself can lead to significant performance improvements. By refining embeddings that capture user and item interactions, the model enhances its ability to generate personalized recommendations. Their work emphasizes the importance of integrating fine-tuned contextual knowledge with LLM reasoning capabilities, showcasing how supervised fine-tuning can bridge the gap between general-purpose LLMs and high-performance recommender systems. |
| Instruction Tuning | Enhances the model’s ability to interpret diverse recommendation queries. | Wu et al. (source) constructs an instruction dataset to bridge the gap between pre-trained LLM knowledge and domain-specific requirements in online job recommendations. By transforming industry-specific data into structured instructions, this method fine-tunes LLMs to understand recruitment-related nuances, improving both recommendation accuracy and fairness. This approach showcases how instruction tuning enables LLMs to adapt without modifying core architectures.
Luo et al. (source) leverages instruction-tuned LLMs for data augmentation, addressing challenges like data sparsity and the long-tail problem in recommendation systems. By synthesizing high-quality training data, instruction tuning enhances the model’s ability to generate more personalized and diverse recommendations. This method is particularly useful in domains where user-item interactions are limited, ensuring better generalization. |
| LoRA (Low-Rank Adaption) | Fine-tunes models efficiently while preserving core parameters. | Bao et al. (source) optimizes Low-Rank Adaptation (LoRA) by incorporating rank decomposition matrices to integrate supplementary information into LLMs while keeping the core parameters frozen. This allows efficient parameter-efficient fine-tuning (PEFT), making the model adaptable without requiring extensive retraining. By leveraging LoRA’s ability to update only specific low-rank components, this method enhances recommendation accuracy while preserving computational efficiency.
Xu et al. (source) takes LoRA further by training domain-specific parameters that act as plug-in modules, allowing seamless adaptation to new tasks without re-training the entire model. This modular approach significantly improves the efficiency of deploying LLMs in diverse recommendation scenarios, ensuring that models can quickly adjust to different domains while maintaining high performance. |
| Direct Utilization | Leverages pre-trained models without modification. | Yao et al. (source) introduces DOKE, a paradigm that enhances LLMs by integrating domain-specific knowledge, making them more effective for practical applications. This approach involves three key steps: extracting relevant knowledge, selecting context-specific information, and representing it in a format that LLMs can understand. By bridging domain knowledge with LLM capabilities, this method significantly improves recommendation accuracy without requiring extensive fine-tuning.
Wang et al. (source) presents Dynamic Reflection with Divergent Thinking (DRDT), a retriever-reranker framework that enhances LLM-based recommendations by modeling the evolving nature of user preferences. DRDT integrates collaborative signals and temporal changes to better predict sequential recommendations, making it particularly useful for dynamic environments where user interests shift over time. This technique ensures that recommendations remain relevant and personalized while maintaining computational efficiency. These two studies highlight how direct LLM utilization—whether through domain knowledge augmentation or dynamic user preference modeling—can significantly enhance recommendation quality without traditional fine-tuning or data-intensive training. |
| Prompt Tuning | Refines specific prompts to optimize responses without changing model parameters. | Li et al. (source) introduces an end-to-end framework that integrates prompt tuning with aspect-based recommendation, enhancing LLMs’ ability to extract personalized aspects from user interactions. By leveraging prompt tuning, the model refines its understanding of user preferences, leading to more accurate and context-aware recommendations. This approach bridges the gap between user-generated content and recommendation quality without requiring extensive fine-tuning.
Liu et al. (source) applies prompt tuning to news recommendation, incorporating a prompt optimizer with an iterative bootstrapping method. This strategy enables LLMs to refine their responses dynamically, improving the relevance and accuracy of news recommendations over time. By continuously optimizing prompts, the framework enhances model adaptability, making it highly effective in scenarios where content evolves rapidly. Both studies demonstrate how prompt tuning serves as a lightweight yet powerful alternative to fine-tuning, allowing LLMs to adapt efficiently to personalized recommendation tasks while minimizing computational costs. |
| In-Context Learning (ICL) | Provides contextual examples within the input to dynamically guide recommendations without altering the model’s structure. | Gao et al. (source) introduces Chat-Rec, a novel paradigm that enhances LLMs for conversational recommendation systems by transforming user profiles and historical interactions into structured prompts. This method leverages in-context learning (ICL) to enable LLMs to dynamically interpret user preferences without requiring fine-tuning. By making recommendations more interactive and explainable, Chat-Rec bridges the gap between static recommendation models and real-time conversational AI.
Che et al. (source) addresses the New Community Cold-Start (NCCS) problem using ICL as a prompting strategy. The study proposes a coarse-to-fine framework that selects effective demonstration examples to construct prompts, allowing LLMs to generate relevant recommendations even in data-sparse environments. By utilizing LLMs’ inference capabilities, this approach improves recommendation quality without requiring retraining, making it efficient for cold-start scenarios. |
Conclusion
The transition to LLM-enhanced recommender systems demands more than just calling an API—it requires architectural rethinking and a layered strategy for adaptation. Whether through full model fine-tuning or prompt-based enhancements, the landscape now offers a broad set of techniques to embed LLM intelligence across the recommendation stack. From constructing embeddings and injecting semantic reasoning to generating explanations and evaluating fairness, LLMs are proving to be composable assets in modern recommender infrastructure.
But with this power comes complexity. The challenge now shifts toward maintaining responsiveness at scale, managing cost-performance trade-offs, and building guardrails for fairness, privacy, and user control. Addressing these concerns benefits from shared experimentation and open frameworks, such as those fostered by LF AI & Data’s GenAI Commons, where community-driven practices help translate research into production-ready solutions. That’s why Part 3 will focus on the operational realities of deploying LLM-based recommenders: cost modeling, hardware acceleration, privacy risks, and ethical pitfalls. Together, these three parts create a full-stack view—from foundational ideas and architectural patterns to real-world constraints and strategic decisions required to deploy the next generation of recommender systems.
Acknowledgment
Special thanks to Ofer Hermoni, Sandeep Jha, and the members of LF AI & Data’s GenAI Commons for their input and collaboration. The group’s open discussions, shared frameworks, and cross-community efforts continue to shape how generative AI—and recommender systems in particular—are advanced in practice.
Reference
- https://arxiv.org/abs/2410.19744
- https://github.com/microsoft/RecAI
- https://arxiv.org/abs/1806.01973
- https://arxiv.org/abs/2303.14524
- https://techblog.rtbhouse.com/large-language-models-in-recommendation-systems/
- Deep Neural Networks for YouTube Recommendations
- Spotify Research blog: Sequential Recommendation via Stochastic Self-Attention
- Prompt Tuning LLMs on Personalized Aspect Extraction for Recommendations
- Improving Sequential Recommendations with LLMs