



By Raghavan Muthuregunathan
Introduction
In today’s software development landscape, efficiently searching through codebases is crucial for productivity. Whether you’re looking for a specific function, debugging an issue, or understanding a new codebase, having a robust code search tool can significantly enhance your workflow. This tutorial will guide you through building a code search engine using purely open-source tools. By leveraging open-source Large Language Models (LLMs), vector search libraries, and sentence embedding models, you can create a powerful and customizable solution.
Building Gen AI Applications with Open Source Tools
While closed-source solutions like OpenAI’s GPT models provide powerful capabilities, it’s possible to achieve similar functionality using open-source alternatives. In this tutorial, we’ll focus on the following open-source tools:
– Ollama (Codestral): An open-source LLM that can generate and understand code.
– Annoy: A library for efficient vector similarity search.
– Sentence BERT: A model for generating sentence embeddings.
Closed Source Equivalents
To understand the significance of these tools, let’s compare them with their closed-source counterparts:
- GPT vs. Codestral: While GPT models from OpenAI are highly advanced, Codestral offers a competitive open-source alternative for code generation and understanding.
- Closed Source Vector Stores vs. Annoy: Closed-source vector stores offer managed services and additional features, but Annoy provides an efficient and scalable open-source solution.
- Embeddings (Ada from OpenAI) vs. Sentence BERT: Ada embeddings from OpenAI are powerful, but Sentence BERT offers a robust and accessible open-source alternative.
Importance of Open Source
Developing with open source tools offers several significant advantages in the field of software engineering and AI application development. Firstly, open source alternatives provide competitive functionality to powerful closed-source solutions, enabling developers to build advanced applications while maintaining independence from proprietary platforms. This democratizes access to cutting-edge technologies and allows for more diverse and innovative solutions. Secondly, open source tools typically offer greater flexibility and customization options, empowering developers to tailor solutions precisely to their needs or to the specific requirements of their projects. This adaptability can lead to more efficient workflows and improved productivity. Lastly, engaging with open source technologies fosters a culture of learning and collaboration within the developer community. By working with transparent, modifiable systems, developers can gain deeper insights into underlying technologies, contribute improvements, and participate in a global ecosystem of shared knowledge and resources. These factors combine to make open source development an attractive and powerful approach for building modern software solutions.
Tutorial: Building Embeddings
To build our code search engine, we first need to generate embeddings for our code snippets. Embeddings are numerical representations of text that capture semantic meaning, making it possible to perform similarity searches. The below example is based on the python but steps 2 through 4 are language agnostic.
Step 1: Install Dependencies
Ensure you have the following dependencies installed:
“`bash
pip install ollama sentence-transformers annoy
“`
Step 2: Generate Embeddings with Sentence BERT
We’ll use Sentence BERT to generate embeddings for our code snippets. Here’s a sample script to achieve this:
“`python
from sentence_transformers import SentenceTransformer
import numpy as np
# Initialize Sentence BERT model
model = SentenceTransformer(‘sentence-transformers/all-MiniLM-L6-v2’)
# Sample code snippets
code_snippets = [
“def add(a, b): return a + b”,
“def multiply(a, b): return a * b”,
“def subtract(a, b): return a – b”
]
# Generate embeddings
embeddings = model.encode(code_snippets)
# Save embeddings
np.save(‘code_embeddings.npy’, embeddings)
“`
This script initializes a Sentence BERT model, generates embeddings for a list of code snippets, and saves them to a file.
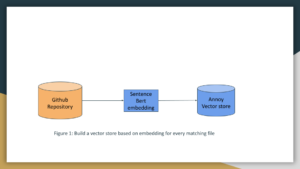
Integrating Annoy for Efficient Search
Annoy (Approximate Nearest Neighbors Oh Yeah) is a library that enables efficient vector similarity searches. We’ll use it to search for code snippets based on their embeddings.
Step 3: Build an Annoy Index
Next, we’ll build an Annoy index using the embeddings generated earlier:
“`python
from annoy import AnnoyIndex
import numpy as np
# Load embeddings
embeddings = np.load(‘code_embeddings.npy’)
# Initialize Annoy index
dimension = embeddings.shape[1]
annoy_index = AnnoyIndex(dimension, ‘angular’)
# Add embeddings to index
for i, embedding in enumerate(embeddings):
annoy_index.add_item(i, embedding)
# Build the index
annoy_index.build(10)
annoy_index.save(‘code_search.ann’)
“`
This script initializes an Annoy index, adds the embeddings, and builds the index for efficient search.
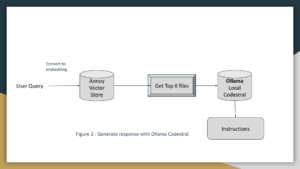
Using Ollama for Code Understanding and Generation
Ollama (Codestral) is an open-source LLM that can understand and generate code. We’ll use it to enhance our code search engine by providing code explanations and generation capabilities. Let’s write the python script that performs search and uses Codestral to generate explanations. This script integrates the components we’ve discussed to perform code searches and generate explanations using Ollama.
“`python
import json
from annoy import AnnoyIndex
from sentence_transformers import SentenceTransformer
import ollama
# Initialize Sentence BERT model
model = SentenceTransformer(‘sentence-transformers/all-MiniLM-L6-v2’)
# Load Annoy index
annoy_index = AnnoyIndex(384, ‘angular’)
annoy_index.load(‘code_search.ann’)
# Load code snippets
with open(‘code_snippets.json’, ‘r’) as f:
code_snippets = json.load(f)
def search_code(query, top_n=5):
# Generate query embedding
query_embedding = model.encode([query])[0]
# Perform search
indices = annoy_index.get_nns_by_vector(query_embedding, top_n)
# Retrieve code snippets
results = [code_snippets[i] for i in indices]
return results
def explain_code(code):
# Use Ollama to generate code explanation
explanation = ollama.generate(code, model=’codestral’)
return explanation
if __name__ == “__main__”:
# Sample query
query = “function to add two numbers”
# Search for code
search_results = search_code(query)
print(“Search Results:”)
for result in search_results:
print(result)
# Generate explanation for the first result
explanation = explain_code(search_results[0])
print(“Code Explanation:”)
print(explanation)
“`
Implementation of this app is based on the work here and here
Conclusion
One limitation of deploying Ollama locally is that we are restricted by the hardware capabilities of the laptop or desktop. By following this tutorial, you’ve learned how to build a code search engine using open-source tools. With Ollama, Annoy, and Sentence BERT, you can create a powerful and efficient search solution tailored to your needs. This approach demonstrates the potential of open-source tools in developing advanced AI applications, offering a viable alternative to closed-source solutions.
References
[2] https://mistral.ai/news/codestral/
[3] https://github.com/spotify/annoy
[5] https://lablab.ai/event/codestral-ai-hackathon/codebasebuddy/codebasebuddy
[6] https://lablab.ai/event/open-interpreter-hackathon/githubbuddy/codebasebuddy
Author Bio:
Raghavan Muthuregunathan is a member of genaicommons.org, leading the Education & Outreach workstream, also the Applications workstream. Apart from his open source contributions, he leads the Search AI organization at Linkedin. He has authored several articles on entrepreneur.com and is an active reviewer for several journals such as IEEE TNNLS, PLOS ONE, ACM TIST. He is also an active hackathon participant on lablab.ai.
Acknowledgement:
We would like to thank Ofer Hermoni, Santhosh Sachindran and the rest of the Gen AI Commons for thoughtful review comments.