



Author: Sandeep Jha
Abstract
Retrieval Augmented Generation (RAG) techniques have emerged as a promising solution to the limitations of Large Language Models (LLMs), such as factual inaccuracies, outdated information, and high operational costs. By integrating external knowledge sources, RAG systems aim to produce more accurate and up-to-date responses. This blog discusses the advancements in RAG through two innovative frameworks: Self-Reflective RAG (SELF-RAG) and Speculative RAG. SELF-RAG introduces a self-reflection mechanism that allows the model to adaptively retrieve information and assess its outputs for relevance and accuracy, thereby enhancing the quality and factuality of responses without compromising the model’s original creativity. Speculative RAG, on the other hand, employs a two-step process with a smaller specialist model generating drafts based on retrieved documents, which are then evaluated by a larger generalist model for accuracy and contextual appropriateness. This division of labor significantly reduces latency and improves efficiency. Both approaches address critical challenges in RAG systems, such as retrieval accuracy and response latency, showcasing the potential for creating more efficient and accurate RAG systems. The advancements discussed in this blog highlight the ongoing evolution of RAG techniques and their significant implications for future applications in the field of Generative AI.
Introduction
Large Language Models (LLMs) demonstrate impressive capabilities but face significant challenges, including factual inaccuracies due to their reliance solely on internal parametric knowledge, outdated and hard-to-update information, difficulty in interpreting and verifying outputs, risks of leaking private data, and high costs associated with their large-scale training and inference. To address this, Retrieval Augmented Generation (RAG) combines the generative abilities of LLMs with external knowledge sources to provide more accurate and up-to-date responses. RAG combines a retriever and a generator in a static setup. The retriever fetches a fixed number of documents relevant to the query, which are added to the prompt for the generator (LLM), hoping the LLM can identify the useful documents and effectively leverage them to generate accurate outputs. This approach is highly effective for open-domain question answering but is less suitable for open-ended, long-form generation. This approach, commonly known as Standard RAG, faces several limitations.
Standard RAG: For Standard RAG, all retrieved documents are incorporated into the prompt as contextual information. This approach retrieves a fixed number of documents for generation, regardless of whether they are truly necessary, and does not reassess the quality of the generated output. Hence this approach encounters several drawbacks: the retrieval phase often has poor precision and recall, leading to the selection of irrelevant information and missing crucial details. In generation, the model might produce unsupported content, known as hallucination, and outputs can suffer from irrelevance, toxicity, or bias, undermining response quality. Augmentation challenges include difficulty integrating retrieved information, resulting in disjointed or incoherent outputs. Redundancy is common when similar information is retrieved multiple times, causing repetitive responses. Additionally, there is a risk that models might overly rely on retrieved information, producing outputs that echo retrieved content without adding new insights.
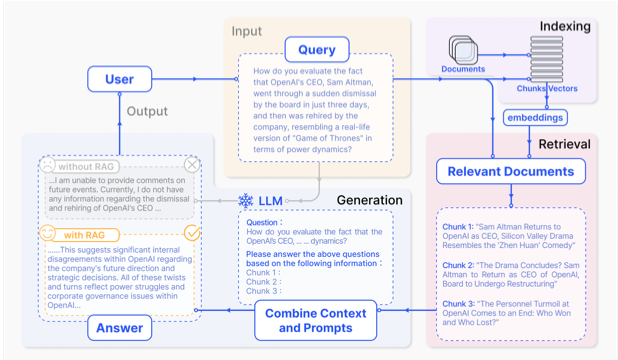 Figure 1: Standard RAG (Source)
Figure 1: Standard RAG (Source)
RAG Enhancements
In the rapidly evolving field of RAG, new techniques are continuously emerging to enhance the effectiveness and efficiency of RAG systems. These enhancement methods can be organized into five categories targeting different aspects of the system: input, retriever, generator, result, and the entire pipeline.
- Input Enhancements: Focus on improving the quality and relevance of the input data fed into the RAG system. This might involve preprocessing steps to refine the query or using advanced techniques to better capture user intent.
- Retriever Enhancements: Aim to increase the efficiency and accuracy of the information retrieval component. Enhancements here could include more sophisticated indexing strategies, employing more advanced neural network architectures, or integrating multiple retrievers to handle different types of data or queries more effectively.
- Generator Enhancements: Focus on refining the output generation phase. This could involve training the generation model with richer datasets, using more complex model architectures, or implementing techniques to ensure the output is both relevant and diverse.
- Result Enhancements: Concerned with improving the final output presented to the user. This could involve post-processing steps, such as re-ranking the outputs based on certain criteria or refining the text to increase clarity and readability.
- Pipeline Enhancements: Aim to optimize the entire RAG pipeline. This could involve integrating the components more tightly, tuning the interaction between the retriever and generator, or employing end-to-end training techniques to improve overall performance.
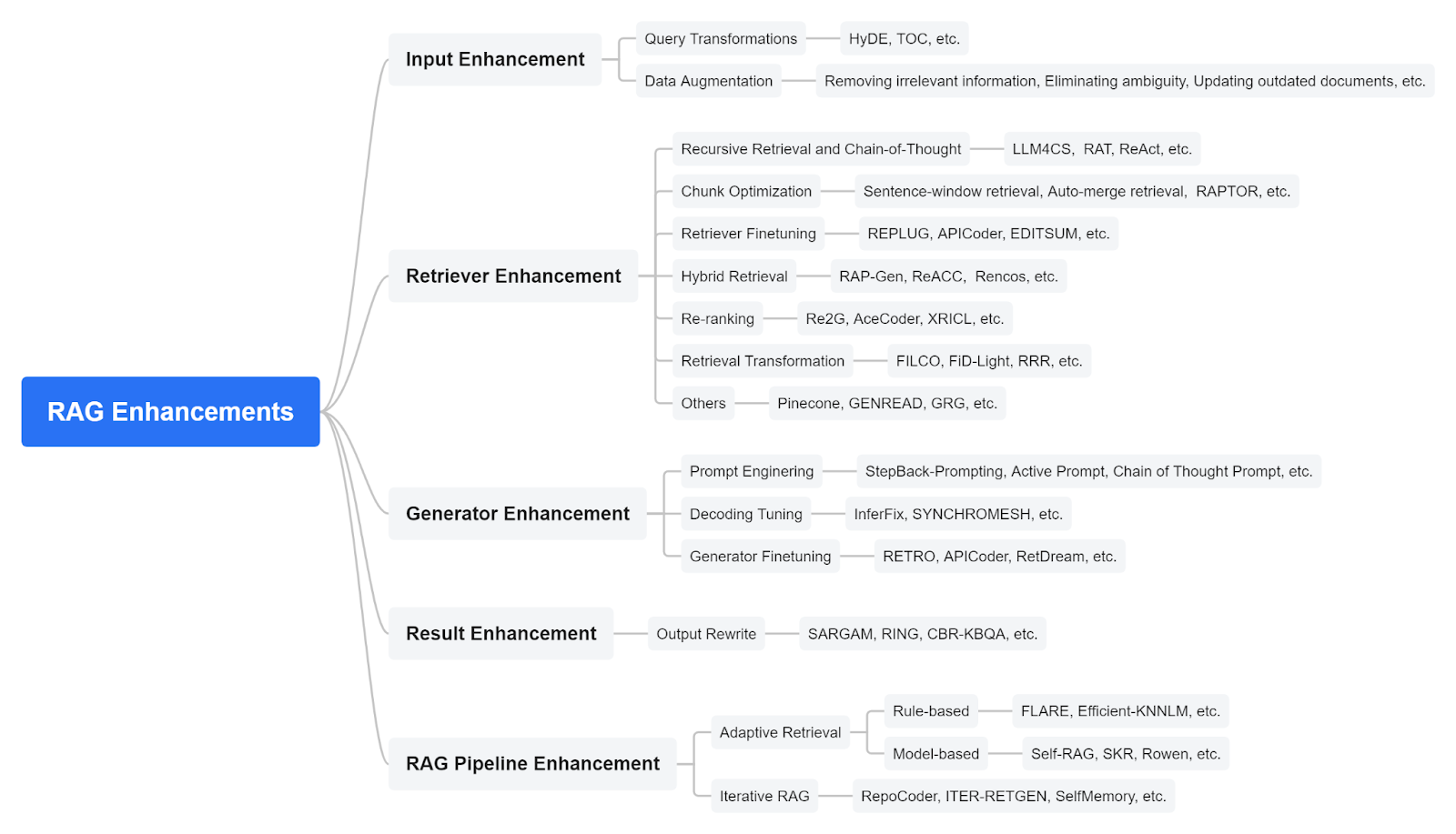 Figure 2: RAG Foundation Taxonomy (Source)
Figure 2: RAG Foundation Taxonomy (Source)
| Enhancement Type | Goal | Examples |
| Input | Improve the quality and relevance of the incoming queries or prompts | Preprocessing steps to refine queries, advanced user-intent capture |
| Retriever | Increase the efficiency and accuracy of retrieving relevant documents | Sophisticated indexing strategies, advanced neural networks, integrating multiple retrievers |
| Generator | Enhance the output generation phase for relevance and diversity | Training on richer datasets, using more complex model architectures, incorporating feedback loops |
| Result | Improve the clarity and quality of the final output presented to users | Post-processing, re-ranking, text refinement to reduce toxicity, bias, or incoherence |
| Pipeline | Optimize the entire RAG workflow and component interactions | Tighter integration between retriever and generator, end-to-end training, better resource scaling |
Figure 3: Overview of RAG Enhancement Categories
In this blog, we will focus on the following advanced techniques: 1) Self-RAG, which part model-based adaptive retrieval to optimize RAG pipeline, 2) Speculative RAG
-
Self-Reflective RAG (SELF-RAG)
SELF-RAG is a framework that enhances the quality and factuality of an LLM through retrieval and self-reflection, without sacrificing LLM’s original creativity and versatility. Unlike Standard RAG methods that retrieve a fixed number of documents regardless of necessity, Self-RAG enables the model to decide when and what to retrieve, ensuring that the incorporated information is relevant and valuable.
Key Components of Self-RAG
- Reflection Tokens: Self-RAG introduces special tokens that guide the model’s behavior during generation. These tokens are categorized into:
- Retrieval Tokens: Indicate the need to retrieve external information.
- Critique Tokens: Allow the model to assess the quality and factual accuracy of its own outputs.
- Adaptive Retrieval: The model learns to retrieve information on-demand, rather than relying on a predetermined number of documents. This ensures that retrieval is contextually appropriate and enhances the relevance of the generated content.
- Self-Reflection Mechanism: By generating critique tokens, the model evaluates its own responses, identifying areas that may require correction or improvement. This self-assessment leads to more accurate and reliable outputs. The system uses four reflection tokens to improve its output quality. IsRel , IsSup, and IsUse serve as critique tokens. IsRel (Information Relevance): Assesses whether a document d is relevant to the query x. Possible outputs: {relevant, irrelevant}. IsSup (Information Support): Evaluates if the document d supports all verification-worthy statements in the output y. Possible outputs: {fully supported, partially supported, no support}. IsUse (Response Usefulness): Rates the usefulness of a response y to the query x. Possible outputs: {5, 4, 3, 2, 1}.
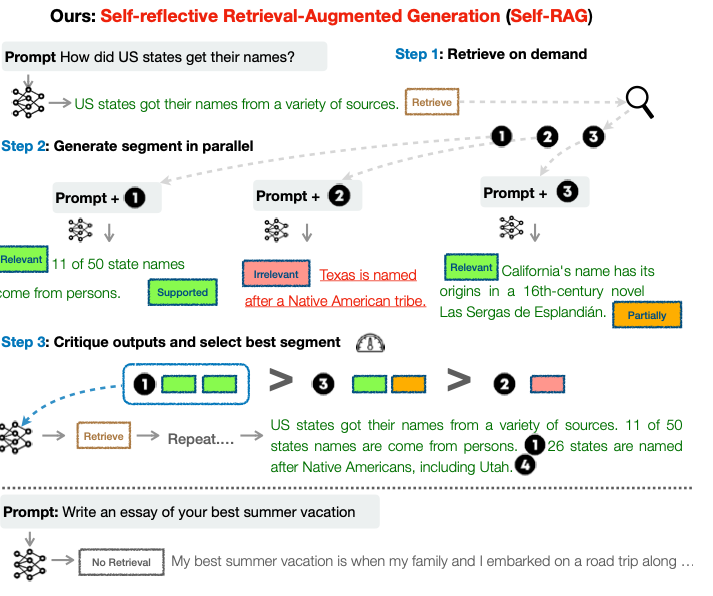 Figure 4: Overview of Self-reflective RAG (Source)
Figure 4: Overview of Self-reflective RAG (Source)
Training
Self-RAG trains two models, Critic and Generator and uses an off-the-shelf Retriever model. The Critic language model is used at training time only and it teaches the Generator model to predict reflection tokens. The Critic model learns to predict the reflection token and is trained on data created by GPT using standard LM objective. The Generator is trained using the next token prediction objective task on diverse instruct following datasets that are augmented with the Critic model and retriever output.
Inference:
 Figure 5: Self-RAG inference algorithm (Source)
Figure 5: Self-RAG inference algorithm (Source)
Performance
SELF-RAG outperforms ChatGPT and retrieval-augmented Llama2-chat on Open-domain QA [1], reasoning, and fact verification tasks, and it shows significant gains in improving factuality and citation accuracy for long-form generations relative to these models.
Challenges That Remain: Self-reflection requires the model to evaluate its outputs critically, which can introduce additional computational costs and potential bottlenecks. Its effectiveness depends heavily on the quality and reliability of the external data sources it accesses.
- Speculative RAG
Speculative RAG is a novel Retrieval Augmented Generation framework that uses a smaller specialist LM to generate draft texts that are then fed to a larger generalist LM to verify and select the best draft. It borrows ideas, particularly from the Speculative decoding approach.
-
- Specialist RAG drafter: A smaller, specialized LLM generates multiple answer drafts in parallel, each based on distinct subsets of retrieved documents. This strategy reduces input token counts per draft and offers diverse perspectives on the evidence.
- Generalist RAG verifier: A larger, generalist LLM evaluates these drafts, selecting the most accurate and contextually appropriate response. This division of labor enhances efficiency, as the smaller model handles the initial drafting, while the more powerful model focuses on verification.
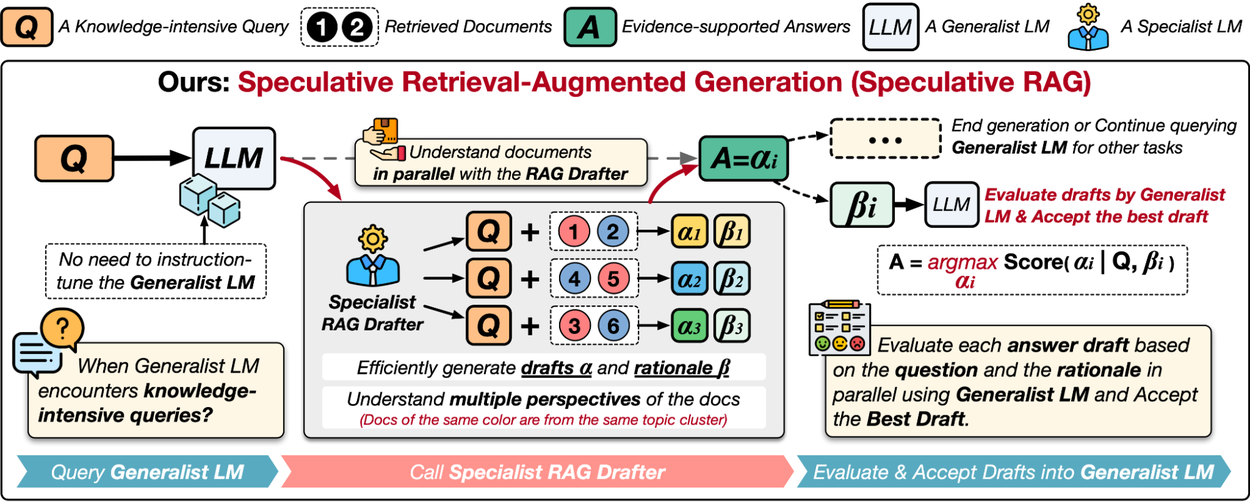 Figure 6: Overview of Speculative RAG (Source)
Figure 6: Overview of Speculative RAG (Source)
Algorithm Steps:
The RAG Drafter is an instruction-tuned model specialized in understanding retrieved documents and efficiently producing faithful rationales. This model plays a central role in generating answer drafts and rationales (Step 4), ensuring that the selected content is both accurate and efficient. In contrast, the Verifier Model, a generalist language model, assesses the confidence of these drafts using its pre-trained capabilities without needing to process all retrieved documents directly (Step 5). By leveraging the rationales produced by the RAG Drafter, the Verifier enhances efficiency, reduces redundancy, and supports the final step of selecting and integrating the best answer (Steps 6 and 7). Together, these models orchestrate an optimized workflow for retrieval, clustering, rationale generation, confidence evaluation, and final answer integration, as outlined below.
- Retrieve relevant documents: Collect documents related to the posed question.
- Cluster documents by perspective: Group the documents based on how they relate to the question, with each cluster representing a unique perspective.
- Select representative documents: From each cluster, pick one document to create a subset that is diverse and minimizes redundancy.
- Generate drafts and rationales: For each subset, use the RAG Drafter model to generate an answer draft and a corresponding rationale, processing them in parallel.
- Compute confidence scores: Employ the generalist language model (Verifier) to calculate a confidence score for each draft based on the question and its rationale.
- Choose the best answer: Select the answer draft with the highest confidence score as the final answer.
- Integrate the final answer: Incorporate the selected answer draft into the output of the generalist language model.
 Figure 7: Speculative RAG Algorithm (source)
Figure 7: Speculative RAG Algorithm (source)
Performance: Accuracy and Latency
Speculative RAG achieves better performance across all benchmarks. For instance, on the PubHealth dataset, Speculative RAG surpasses the best baseline, Mixtral-Instruct-8x7B, by 12.97%. [3]
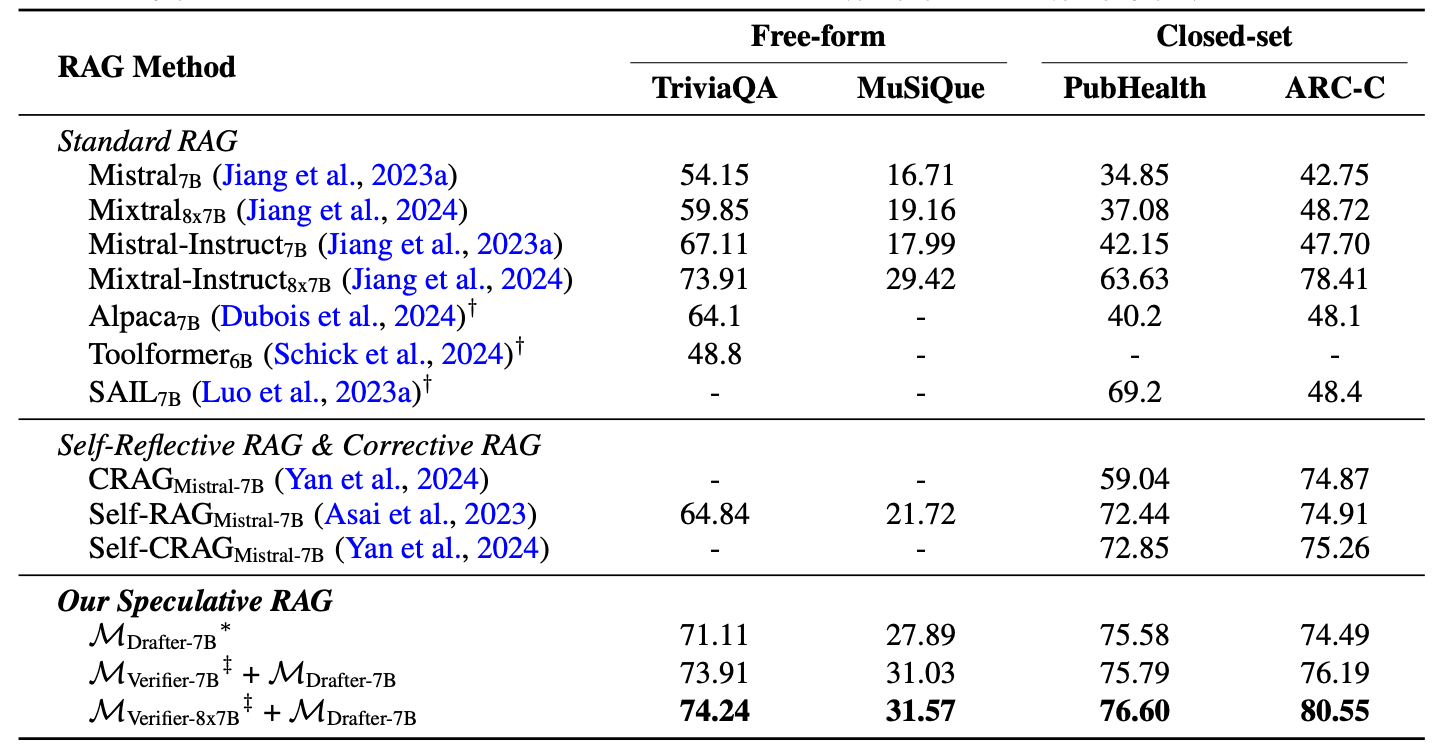 Figure 8: RAG results on Open Source Datasets (source)
Figure 8: RAG results on Open Source Datasets (source)
Speculative RAG, leveraging a smaller drafter and parallel draft generation, consistently achieves lower latency across all datasets, reducing latency by 51% on the PubHealth dataset compared to standard RAG systems
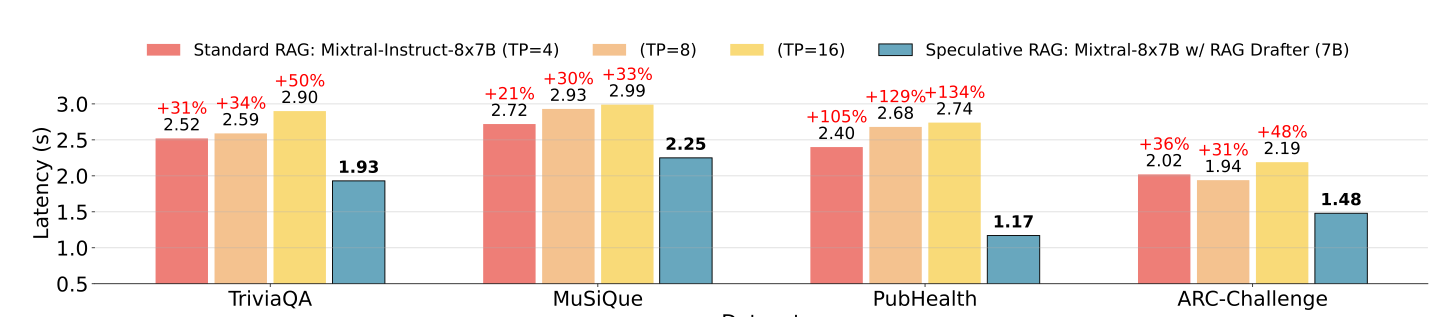 Figure 9: Latency analysis of Standard and speculative RAG (source)
Figure 9: Latency analysis of Standard and speculative RAG (source)
Open Source Tools for RAG Frameworks
Open-source tools play a vital role in implementing advanced RAG techniques like SELF-RAG and Speculative RAG. Milvus, an open-source vector database, supports scalable and efficient dense retrieval for RAG systems. Frameworks like Hugging Face Transformers, LangChain, and Haystack enable seamless integration of retrieval, generation, and self-reflection mechanisms. Platforms like Ray and Kubernetes manage distributed RAG pipelines for scalability and efficiency. These open-source solutions empower developers to build cutting-edge RAG systems with greater flexibility and cost-effectiveness.
Conclusion
Advanced RAG techniques like Speculative RAG and Self RAG address key challenges of latency and retrieval accuracy, offering complementary solutions. Speculative RAG reduces latency with a smaller drafter model and parallel generation, achieving significant efficiency gains. Self RAG enhances precision by iteratively refining retrievals for better query alignment. Together, these approaches demonstrate the potential to create faster, more accurate RAG systems, paving the way for innovative applications and future advancements in the field.
References
- Self-RAG
- Corrective RAG
- Speculative RAG
- RAG survey paper 2023
- RAG survey paper 2024
- ACL 2023 Tutorial: Retrieval-based Language Models and Applications
Author Bio:
Sandeep Jha is a member of genaicommons.org, contributing to the Education & Outreach workstream. Apart from his open source contributions, he leads the Generative AI strategy at Linkedin. He has authored several articles on Forbes.com and actively reviews for various journals and prestigious conferences, including Knowledge and Information Systems and the ACM Special Interest Group on Information Retrieval (SIGIR).
Acknowledgement:
We would like to thank Ofer Hermoni, Raghavan Muthuregunathan and the rest of the Gen AI Commons for thoughtful review comments.