



We are thrilled to announce that the BAAI Aquila-VL-2B model, developed by the BAAI research team, has earned the prestigious Class I “Open Science” rating from LF AI & Data’s Model Openness Framework (MOF). This milestone distinguishes Aquila-VL-2B as the first model to receive this recognition, underscoring its exemplary commitment to openness and transparency in AI development.
The model’s parameters, training code, data of this model, and other key research artifacts are fully accessible under open-source licenses, offering researchers worldwide streamlined opportunities for analysis, replication, and application.
 Figure 1. Screenshot of Aquila-VL-2B Class I Certification
Figure 1. Screenshot of Aquila-VL-2B Class I Certification
LF AI & Data’s MOF is a comprehensive framework designed to objectively evaluate and classify AI models based on their completeness and openness in reproducibility, transparency, and usability. Grounded in the principles of open science, it features a tiered classification system with clear metrics and guidelines to assess and promote AI model openness.
The MOF defines three progressively broader classes of model openness:

Figure 2. The MOF Classes
- Class III – Open Model: The entry-level tier, Class III, requires the public release of the core model, including its architecture, parameters, and basic documentation, under open licenses. While this allows others to use, analyze, and build on the model, it offers limited insight into the underlying development process.
- Class II – Open Tooling: Building on the foundation of Class III, Class II mandates the release of the full suite of code used for training, evaluation, and deployment of the model, along with key datasets. This enables the community to validate the model and explore potential issues, making it a critical step toward reproducibility and transparency.
- Class I – Open Science: The highest level, Class I, requires the release of all artifacts in adherence to open science principles. Beyond the requirements of Class II, it includes raw training datasets, a detailed research paper documenting the entire model development process, intermediate checkpoints, log files, and other relevant materials. This level provides comprehensive transparency into the end-to-end development pipeline, fostering collaboration, auditing, and cumulative progress in AI research.
By laying out these requirements, the MOF provides both a north star to strive for and a practical roadmap to get there. It turns openness from an abstract ideal to an actionable framework. Model producers have clear guideposts for what and how to release. Model consumers can readily discern the degree of openness and make informed usage decisions.
The Aquila-VL-2B model is constructed on the robust LLaVA-OneVision framework, utilizing Qwen-2.5-1.5B as its language tower and trained with the Infinity-MM dataset, a multimodal instruction dataset in the tens of millions, which is also open-sourced by the BAAI team. This innovative design, combined with the use of high-quality data, positions Aquila-VL-2B to achieve commendable performance among models of similar scale, as shown in Table 1.
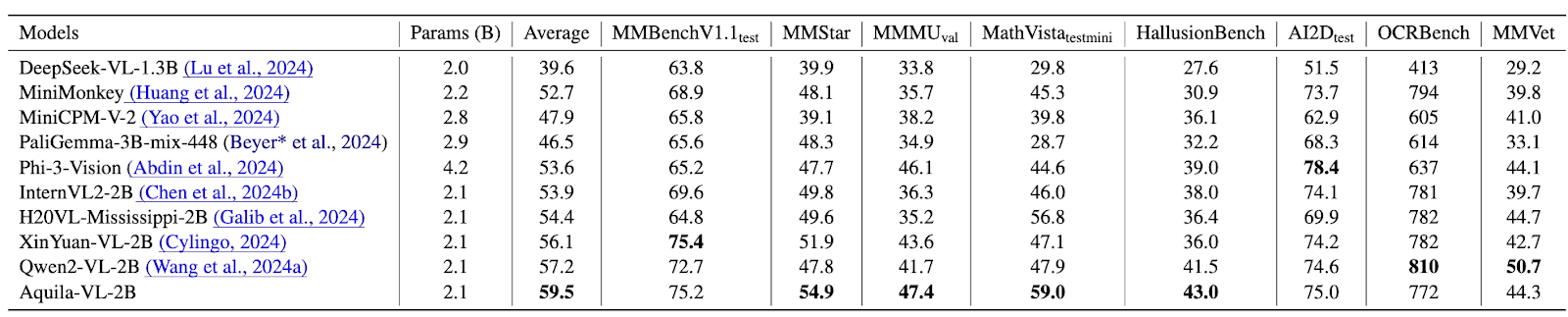
Table 1. Analysis of Aquila-VL-2B’s Evaluation Results on Multimodal Benchmarks
View Aquila-VL-2B at MOF:https://mot.isitopen.ai/model/1130
Download Aquila-VL-2B Model:https://huggingface.co/BAAI/Aquila-VL-2B-llava-qwen
Download Infinity-MM Dataset(Huggingface):https://huggingface.co/datasets/BAAI/Infinity-MM
Download Infinity-MM Dataset:https://www.modelscope.cn/datasets/BAAI/Infinity-MM
Material Article:https://arxiv.org/abs/2410.18558
LF AI & Data Resources
- Learn about membership opportunities
- Explore the interactive landscape
- Check out our technical projects
- Join us at upcoming events
- Read the latest announcements on the blog
- Subscribe to the mailing lists
- Follow us on Twitter or LinkedIn