



As the software industry navigates the complexities of AI and open AI principles, several challenges have emerged. LF AI & Data is at the forefront of addressing these issues through its Model Openness Framework (MOF). The MOF is a ranked classification system that rates machine learning models based on their completeness and openness, following principles of open science, open source, open data, and open access. It requires specific components of the model development lifecycle to be included and released under appropriate open licenses. This framework aims to prevent misrepresentation of models claiming to be open, guide researchers and developers in providing all model components under permissive licenses, and help individuals and organizations identify models that can be safely adopted without use restrictions. By promoting transparency and reproducibility, the MOF combats “openwashing”‘ practices and establishes completeness and openness as primary criteria alongside the core tenets of responsible AI.
In this series, we will explore the various challenges that led the LF AI & Data community to collaborate on establishing the MOF and discuss how this framework addresses said industry challenges.
Challenge #1:
How to Ensure Transparency in AI
One of the current challenges in Generative AI is promoting AI products or projects as “open” or “open source” without truly adhering to openness principles. This practice hampers collaboration and innovation, reduces the credibility of genuine open source initiatives, and complicates efforts to ensure fairness, accountability, and the responsible use of AI technologies.
Problematic practices include releasing parts of an AI model while omitting crucial components like datasets and documentation and using open source licenses in combination slightly modified to limit or restrict the use. These practices obscure critical details, affecting usability and transparency.
The LF AI & Data’s Model Openness Framework aims to address these challenges by establishing clear standards, diligent verification, and education to help users make informed decisions. This framework promotes genuine openness by ensuring that all components of AI models are declared with clear licensing terms. This approach supports the fair, accountable, and responsible use of AI technologies, fostering a trustworthy and innovative AI ecosystem.
Model Openness Framework – Open AI
To avoid using openwashed models, ensure you are truly open by checking that all components are accessible and appropriately licensed. The Linux Foundation AI & Data Generative AI Commons has developed the Model Openness Framework to help with this.

By following these steps and leveraging the resources provided by the Linux Foundation AI & Data Generative AI Commons, you can avoid the pitfalls of openwashing and contribute to a more trustworthy AI ecosystem.
Stay tuned for more insights into these critical issues and how LF AI & Data is working to foster a truly open AI ecosystem.
Model Openness Tool
The implementation of the Model Openness Tool (MOT) is a cornerstone effort in operationalizing the MOF. By bridging the gap between theoretical frameworks and practical application, the MOT empowers users to evaluate and understand the openness of their machine learning models systematically.
The creation of MOT was driven by the necessity for a transparent and straightforward mechanism to assess model compliance with the MOF standards. A series of 16 comprehensive questions were developed to cover various aspects of model development, deployment, and maintenance. These questions are designed to extract detailed information about the model that are critical for determining its level of openness.
The MOT operates through a user-friendly interface where users input responses to the predefined questions. Each response is evaluated against the MOF criteria to ascertain the degree of openness. The tool then employs an algorithm to calculate a cumulative score, which categorizes the model into one of three openness levels: 1 (closed), 2 (partially open), or 3 (fully open).
Users interact with the MOT through a straightforward web-based form or within their local environments, depending on the implementation. Upon completion of the questionnaire, the tool processes the inputs using a scoring algorithm that integrates both qualitative assessments and quantitative measures. The final output is a detailed report that not only provides the openness score but also highlights areas where the model excels and where it could improve in terms of openness.
The primary benefit of the MOT is its ability to address the complexities associated with machine learning model components and their licensing. By providing a clear and concise evaluation, the MOT helps users identify potential restrictions and freedoms associated with the use of their models. This clarity is invaluable for developers and organizations aiming to align their models with open-source standards and practices, ensuring compliance and fostering transparency within the community.
Upcoming Blogs: A Closer Look at Open AI Challenges
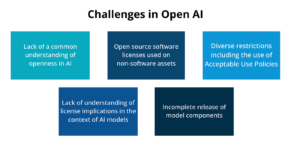
In our upcoming blog posts, we will delve into further complexities surrounding open AI. These challenges include the application of open source software licenses to non-software assets, the implications of diverse restrictions such as Acceptable Use Policies, the common misunderstandings regarding license implications for AI models, and the issues arising from incomplete release of model components. Additionally, we will explore how the Model Openness Framework (MOF) effectively navigates and addresses these open AI challenges.
To learn more and get involved:
- Explore the Model Openness Tool here
- Explore the full Model Openness Framework here
- Join the Generative AI Commons community and mailing list here
- Advocate for the use of MOF in your organization and network
LF AI & Data Resources
- Learn about membership opportunities
- Explore the interactive landscape
- Check out our technical projects
- Join us at upcoming events
- Read the latest announcements on the blog
- Subscribe to the mailing lists
- Follow us on Twitter or LinkedIn