

Last week we were happy to finally release v2 of DocArray, a sandbox project under the LF AI & Data Foundation, released under the open-source Apache-2.0 License.
DocArray is a library for representing, storing, and sending multimodal data, especially focused on machine learning. The new version is a complete rewrite from the ground up, featuring a unified API for several vector databases and Pydantic-style syntax.
DocArray handles your data while integrating seamlessly with the rest of your Python and ML ecosystem:
- Native compatibility for NumPy, PyTorch, and TensorFlow, including for model training use cases
- Built on Pydantic and out-of-the-box compatible with FastAPI and Jina
- Support for vector databases like Weaviate, Qdrant, ElasticSearch, and HNSWLib
- Send data as JSON over HTTP or as Protobuf over gRPC
What’s new in DocArray v2?
If you’ve used older versions of DocArray, you may be familiar with its dataclass API.
DocArray v2 is that idea, taken seriously. Every document is created through the dataclass-like interface, courtesy of Pydantic.
This gives the following advantages:
- Flexibility: No need to conform to a fixed set of fields — your data defines the schema.
- Multimodality: Easily store multiple modalities and multiple embeddings in the same Document.
- Language agnostic: At their core, Documents are just dictionaries. This makes it easy to create and send them from any language, not just Python.
You may also be familiar with our old Document Stores for vector database integration. They are now called Document Indexes and offer the following improvements:
- Hybrid search: You can now combine vector search with text search and even filter by arbitrary fields.
- Production-ready: The new Document Indexes are a much thinner wrapper around the various vector DB libraries, making them more robust and easier to maintain.
- Increased flexibility: We strive to support any configuration or setting that you could perform through the DB’s first-party client.
For now, Document Indexes support Weaviate, Qdrant, ElasticSearch, and HNSWLib, with more to come.
Check our release note to see the full changelog.
Using DocArray
DocArray makes representing, storing, and sending multimodal data easily, especially if you’re focused on machine learning. Let’s dig in a bit deeper.
Represent
DocArray allows you to represent your data, in an ML-native way. This is useful for different use cases:
- You are training a model: There are tensors of different shapes and sizes flying around, representing different things, and you want to keep a straight head about them.
- You are serving a model: For example through FastAPI, and you want to specify your API endpoints.
- You are parsing data: For later use in your ML or data science applications.
Coming from Pydantic? You should be happy to hear that DocArray is built on top of, and is fully compatible with, Pydantic! Also, we have a dedicated section just for you!
Put simply, DocArray lets you represent your data in a data class-like way, with ML as a first-class citizen:
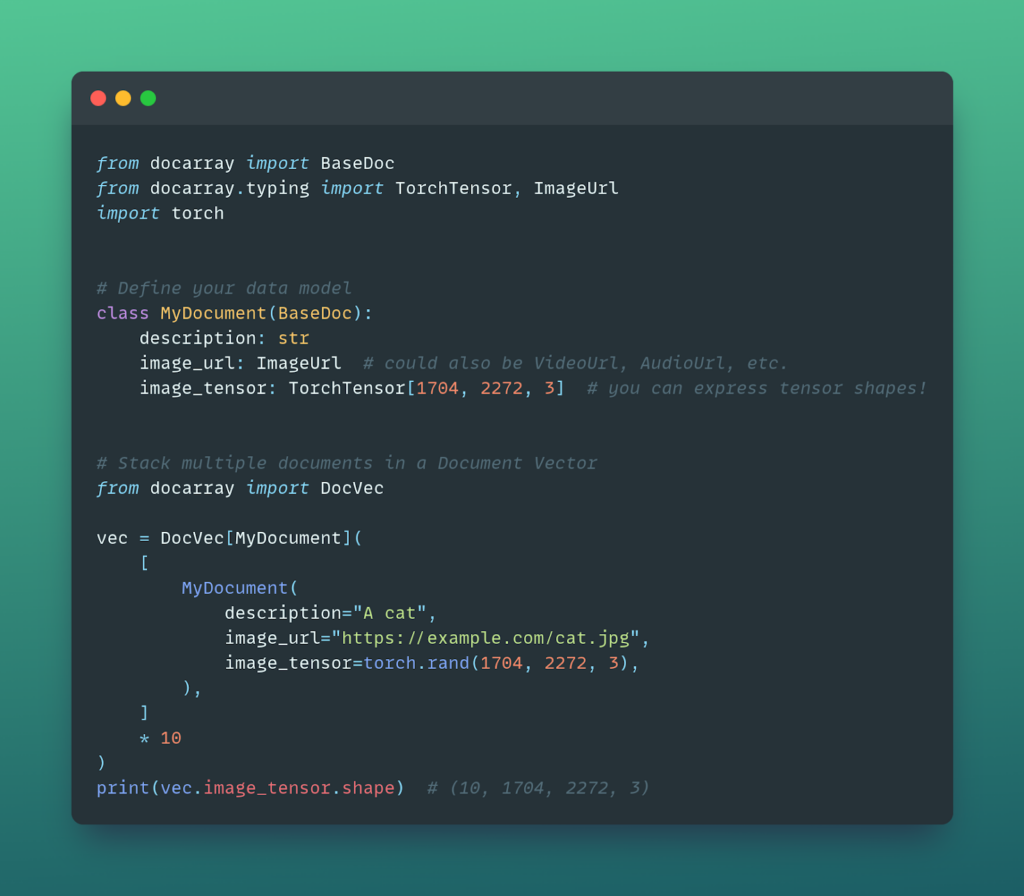
Send
DocArray allows you to send your data in an ML-native way.
This means there is native support for Protobuf and gRPC, on top of HTTP and serialization to JSON, JSONSchema, Base64, and Bytes.
This is useful for different use cases:
- You are serving a model, for example through Jina or FastAPI
- You are distributing your model across machines and need to send your data between nodes
- You are building a microservice architecture and need to send your data between microservices
Whenever you want to send your data, you need to serialize it, so let’s take a look at how that works with DocArray:
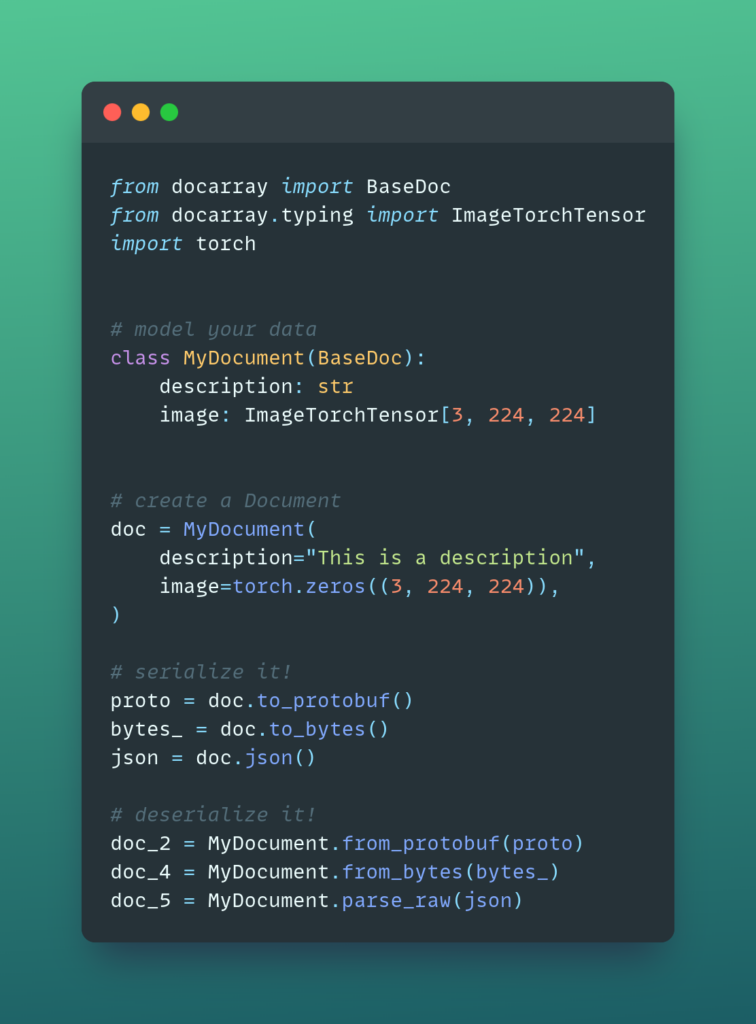
Store
Once you’ve modeled your data, and maybe sent it around, usually you want to store it somewhere. DocArray has you covered!
Document Stores let you, well, store your Documents, locally or remotely, all with the same user interface:
- On disk as a file in your local file system
- On AWS S3
- On Jina AI Cloud
Document Indexes let you index your Documents in a vector database for efficient similarity-based retrieval.
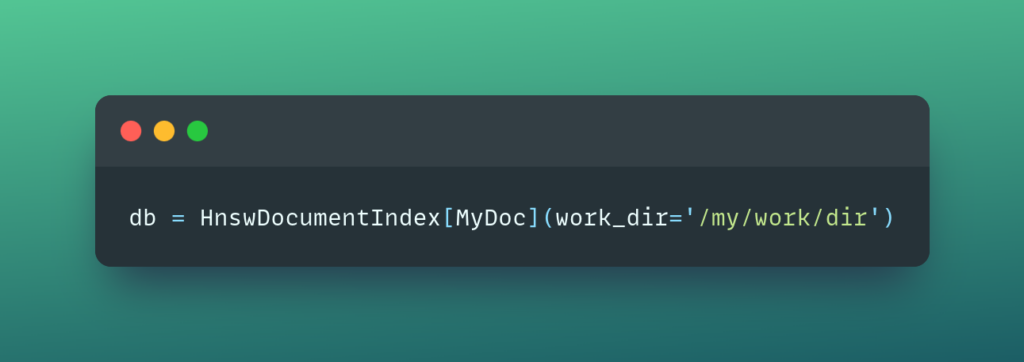
This is useful for:
- Augmenting LLMs and Chatbots with domain knowledge (Retrieval Augmented Generation)
- Neural search applications
- Recommender systems
Currently, Document Indexes support Weaviate, Qdrant, ElasticSearch, and HNSWLib, with more to come!
Installation
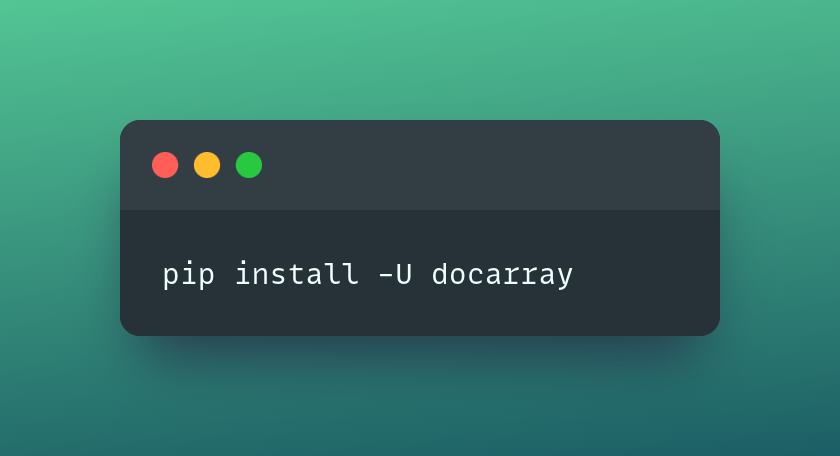
To install DocArray from the CLI, run the following command:
Get started with DocArray v2
To get started:
Get involved!
If you use DocArray or want to get involved in its development, we’d love to see you on our Discord server. Come say hi and make your first contribution to the project!