

By: Animesh Singh, Christian Kadner, Tommy Chaoping Li
Three pillars of AI lifecycle: Datasets, Models and Pipelines
In the AI lifecycle, we use data to build models for decision automation. Datasets, Models, and Pipelines (which take us from raw Datasets to deployed Models) become the three most critical pillars of the AI lifecycle. Due to the large number of steps that need to be worked on in the Data and AI lifecycle, the process of building a model can be bifurcated amongst various teams and large amounts of duplication can arise when creating similar Datasets, Features, Models, Pipelines, Pipeline tasks, etc. This also poses a strong challenge for traceability, governance, risk management, lineage tracking, and metadata collection.
Announcing Machine Learning eXchange (MLX)
To solve the problems mentioned above, we need a central repository where all the different asset types like Datasets, Models, and Pipelines are stored to be shared and reused across organizational boundaries. Having opinionated and tested Datasets, Models, and Pipelines with high quality checks, proper licenses, and lineage tracking increases the speed and efficiency of the AI lifecycle tremendously.
To solve the above challenges, IBM and Linux Foundation AI and Data(LFAI and Data) are joining hands to announce Machine Learning eXchange (MLX), a Data and AI Asset Catalog and Execution Engine, in Open Source and Open Governance.
Machine Learning eXchange (MLX) allows upload, registration, execution, and deployment of:
- AI pipelines and pipeline components
- Models
- Datasets
- Notebooks

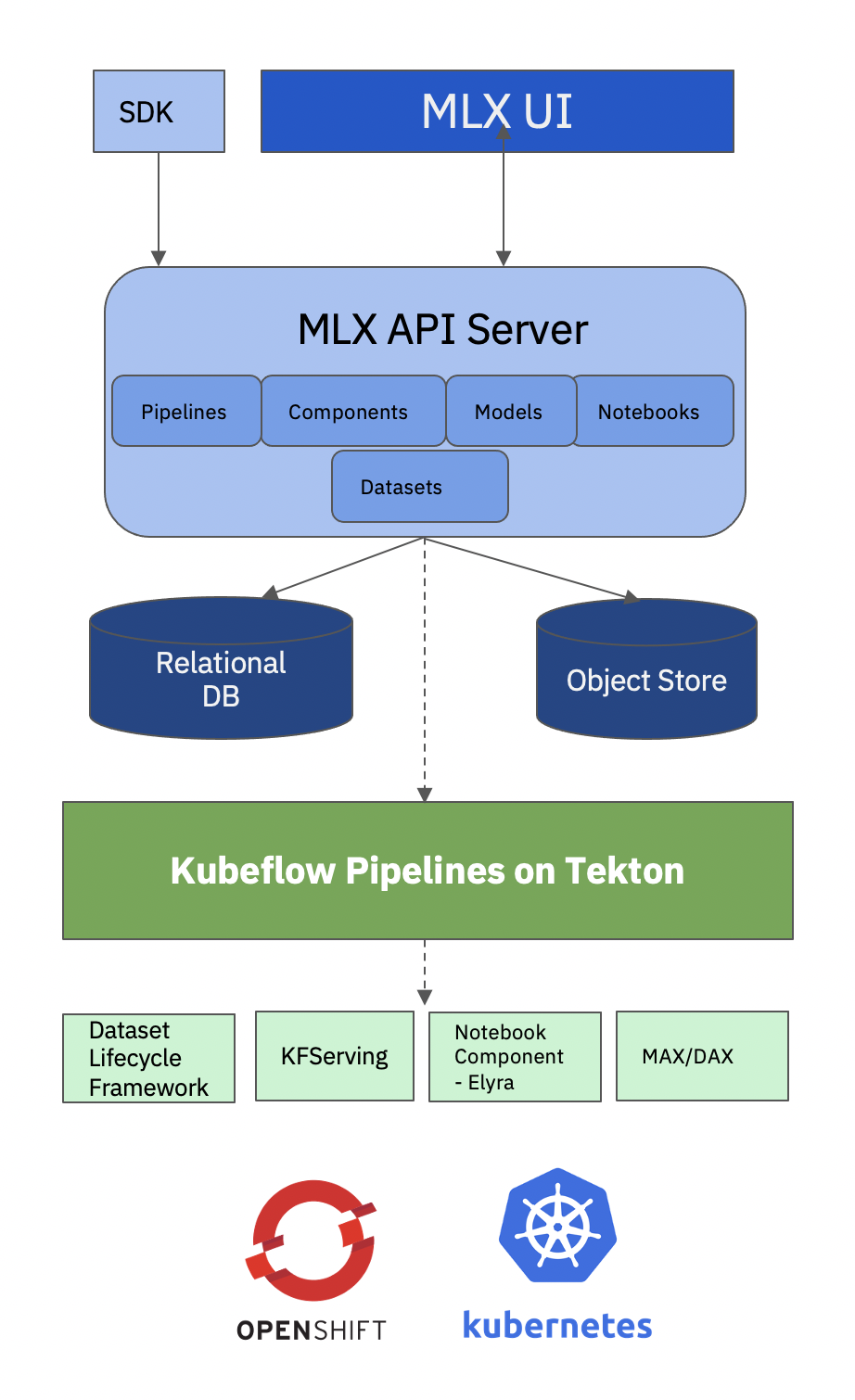
MLX Architecture
MLX provides:
- Automated sample pipeline code generation to execute registered models, datasets, and notebooks
- Pipelines engine powered by Kubeflow Pipelines on Tekton, the core of Watson Studio Pipelines
- Registry for Kubeflow Pipeline Components
- Dataset management by Datashim
- Serving engine by KFServing
MLX Katalog Assets
Pipelines
In machine learning, it is common to run a sequence of tasks to process and learn from data, all of which can be packaged into a pipeline.
ML Pipelines are:
- A consistent way for collaborating on data science projects across team and organization boundaries
- A collection of coarse grained tasks encapsulated as pipeline components to be snapped together like lego bricks
- A one-stop shop for people interested in training, validating, deploying, and monitoring AI models
Some sample Pipelines included in the MLX catalog:
- Trusted AI Pipeline (with AI Fairness 360 and Adversarial Robustness 360)
- Hyperparameter Tuning
- Nested Pipeline
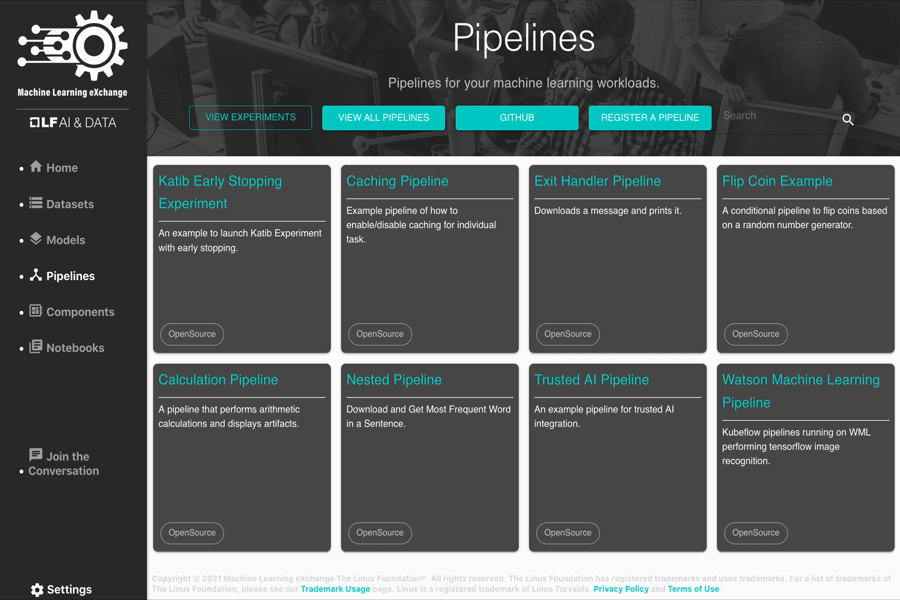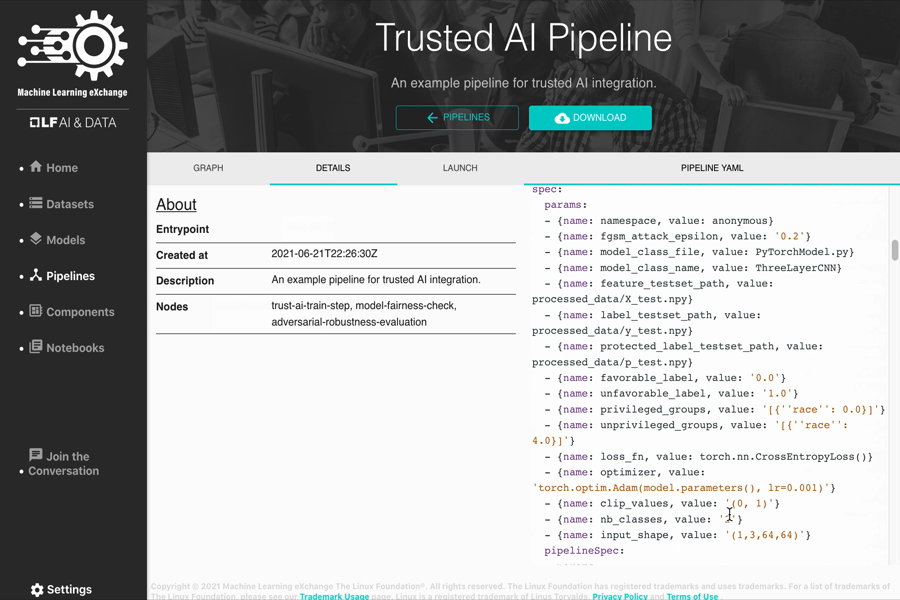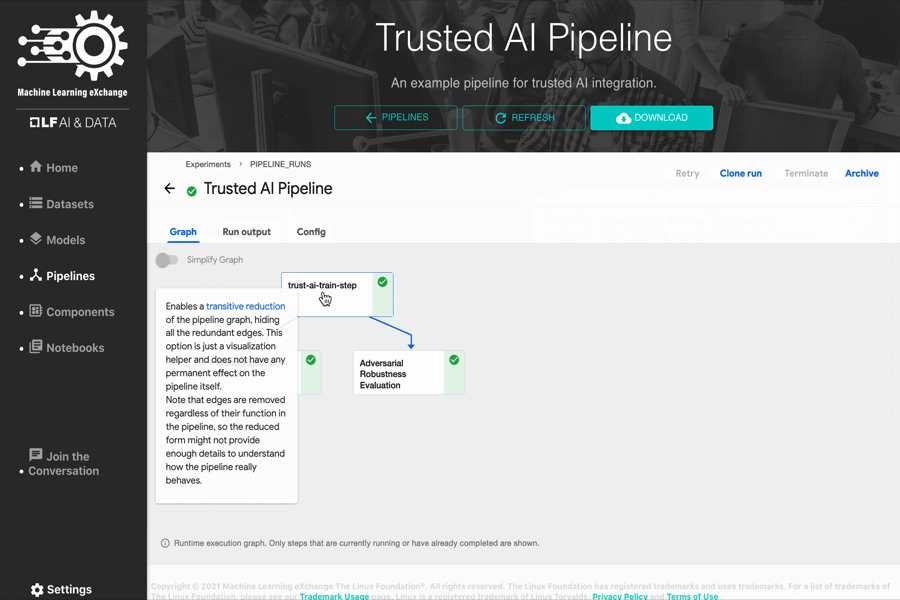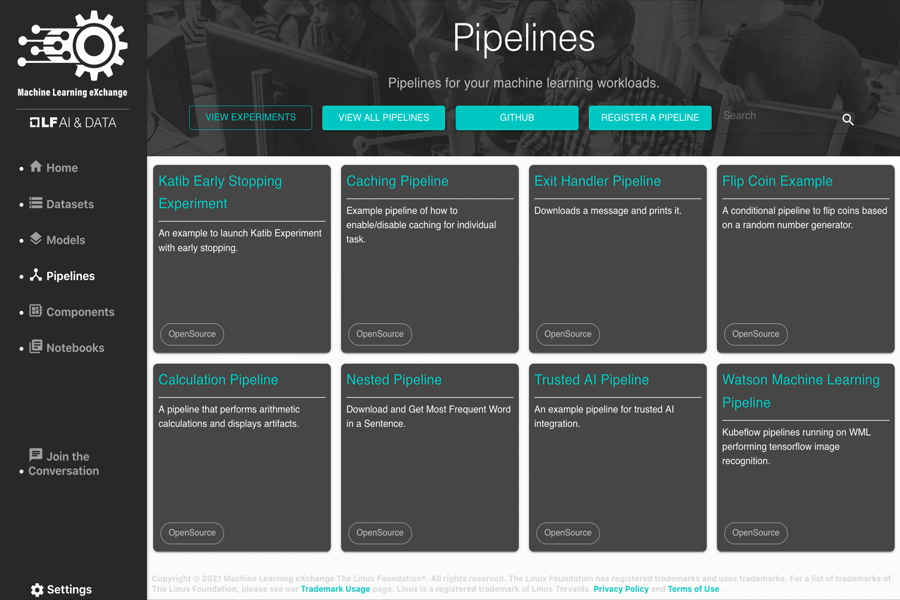
Pipeline Components
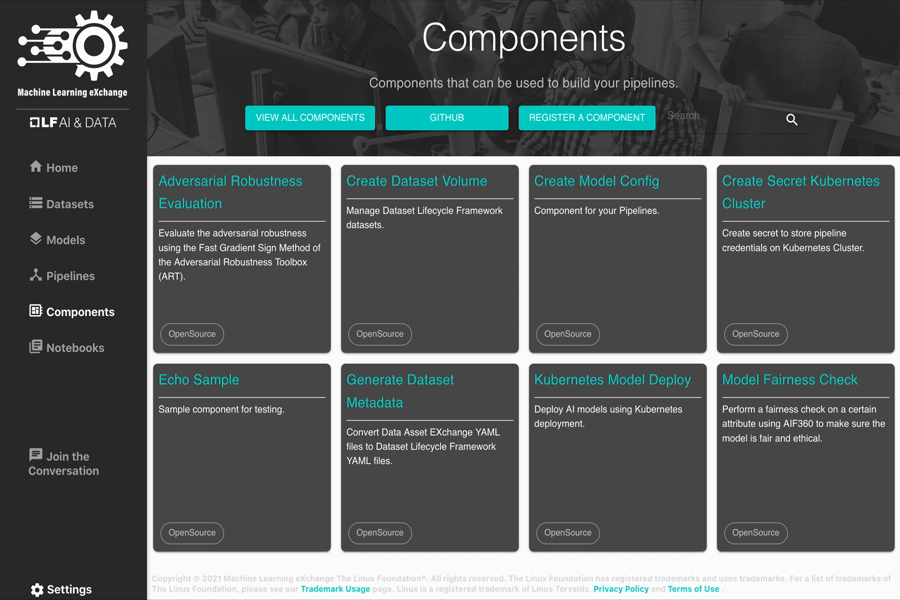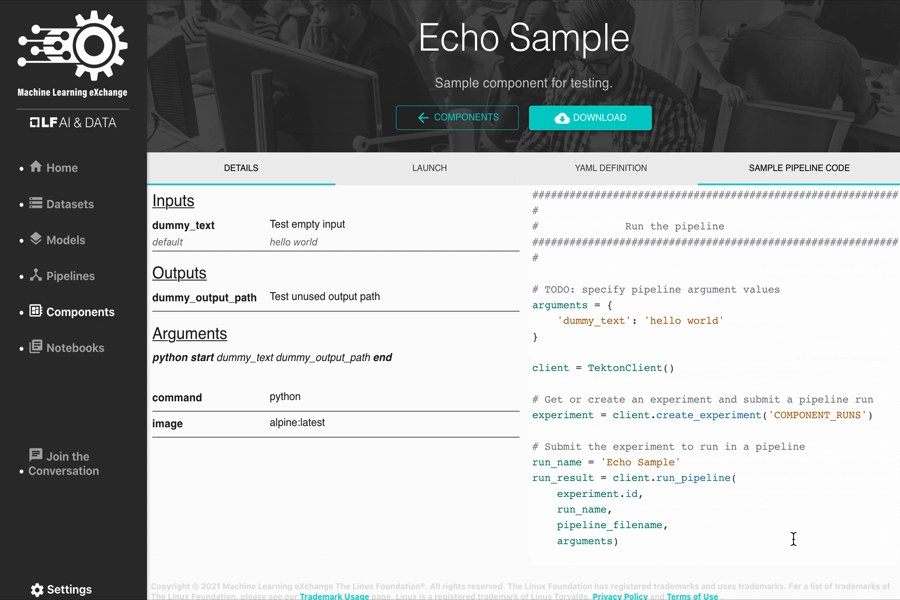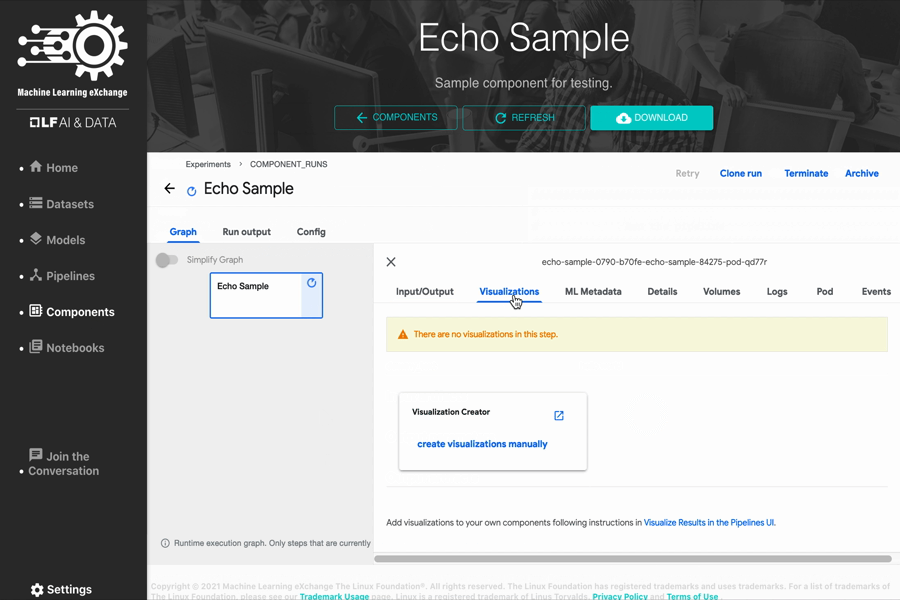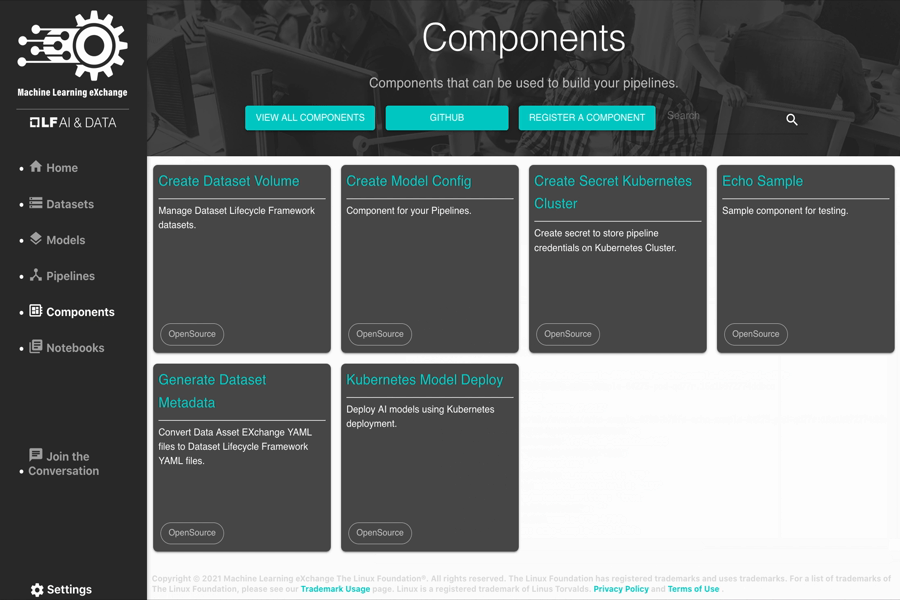
A pipeline component is a self-contained set of code that performs one step in the ML workflow (pipeline), such as data acquisition, data preprocessing, data transformation, model training, and so on. A component is a block of code performing an atomic task and can be written in any programming language and using any framework.
Some sample pipeline components included in the MLX catalog:
- Create Dataset Volume with DataShim
- Deploy a Model on Kubernetes
- Adversarial Robustness Evaluation
- Model Fairness Check
Models
MLX provides a collection of free, open source, state-of-the-art deep learning models for common application domains. The curated list includes deployable models that can be run as a microservice on Kubernetes or OpenShift and trainable models where users can provide their own data to train the models.
Some sample models included in the MLX catalog:
Datasets
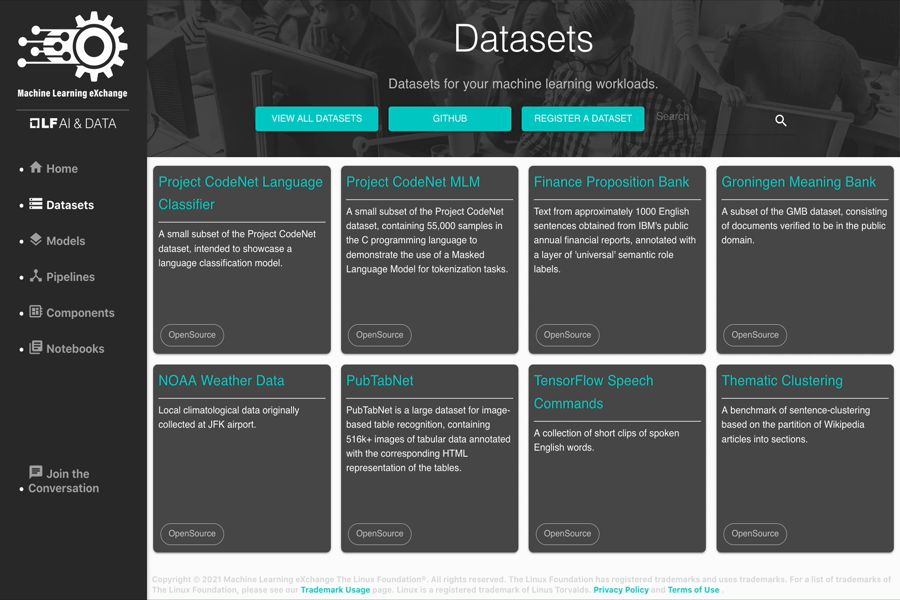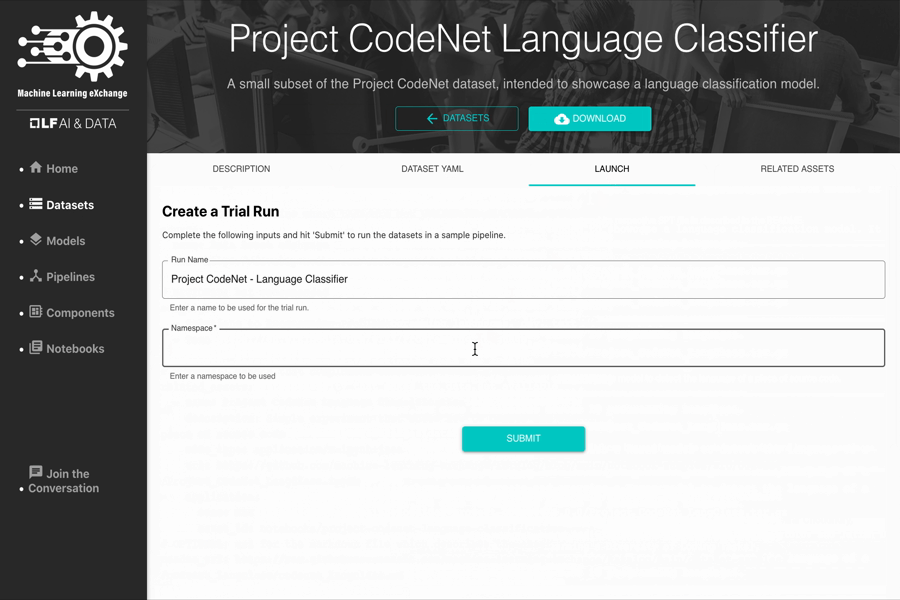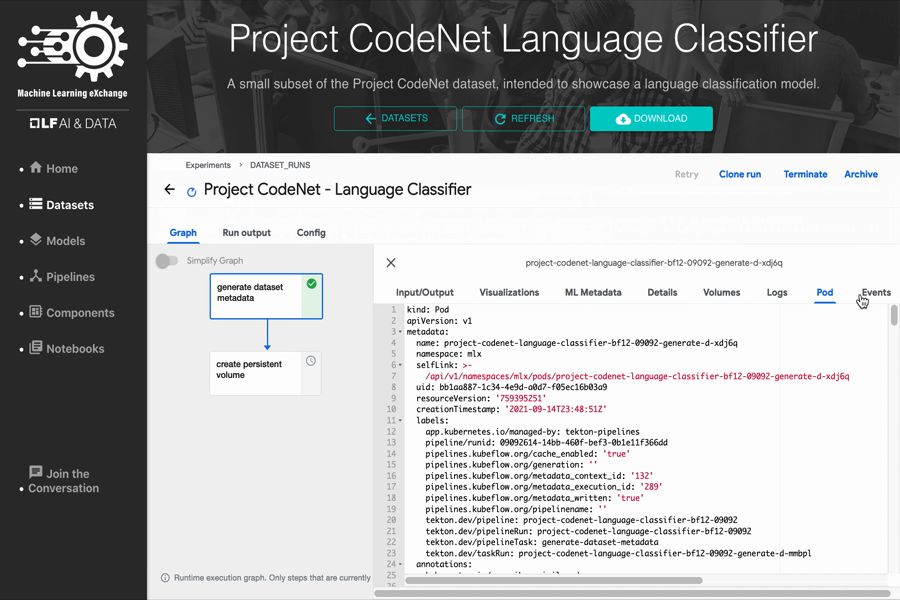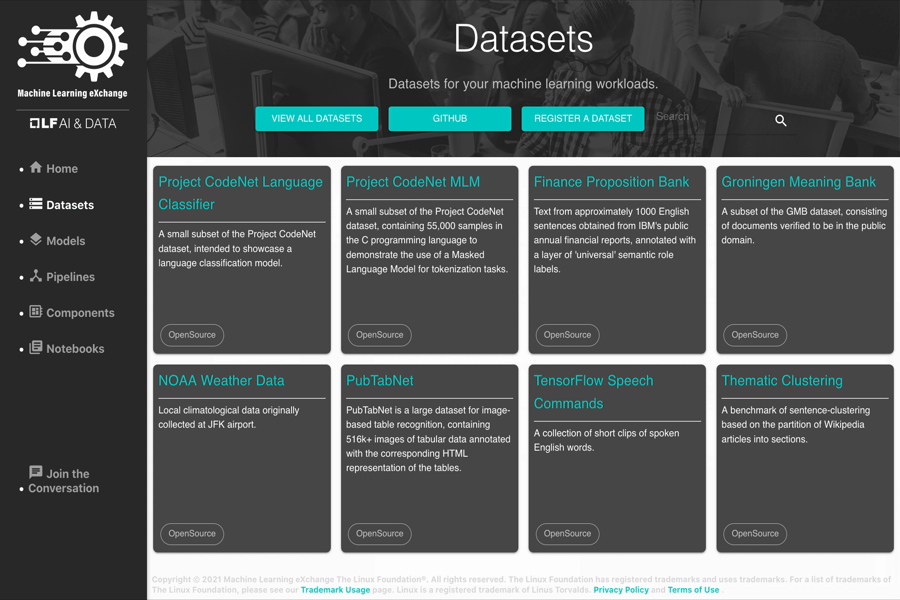
The MLX catalog contains reusable datasets and leverages Datashim to make the datasets available to other MLX assets like notebooks, models, and pipelines in the form of Kubernetes volumes.
Sample datasets contained in the MLX catalog include:
- Finance Proposition Bank
- NOAA Weather Data – JFK Airport
- Thematic Clustering of Sentences
- TensorFlow Speech Commands
Notebooks
Jupyter notebook is an open-source web application that allows data scientists to create and share documents that Jupyter notebook is an open-source web application that allows data scientists to create and share documents that contain runnable code, equations, visualizations, and narrative text. MLX can run Jupyter notebooks as self-contained pipeline components by leveraging the Elyra-AI project.
Sample notebooks contained in the MLX catalog include:
- AIF360 Bias Detection
- ART Poisoning Attack
- JFK Airport Analysis
- Project CodeNet Language Classification
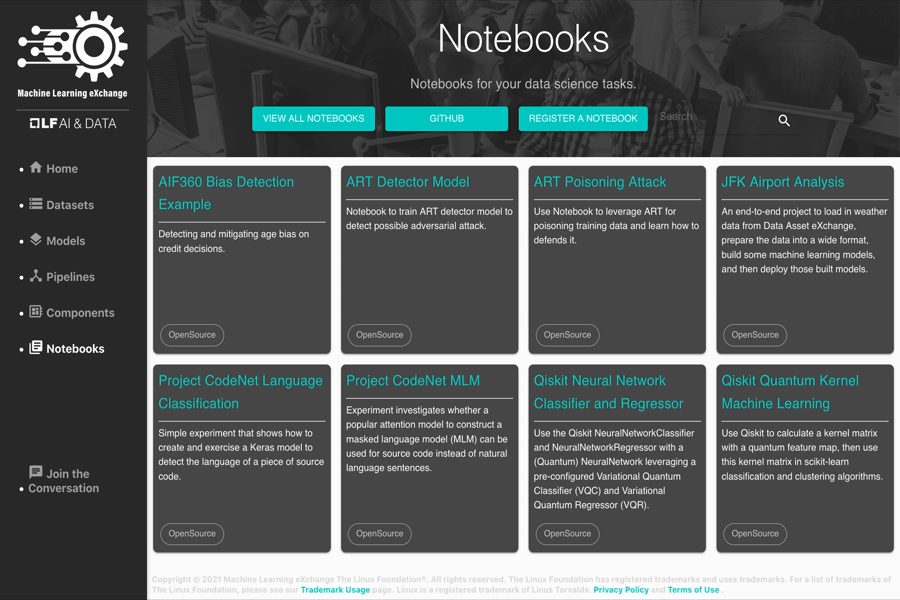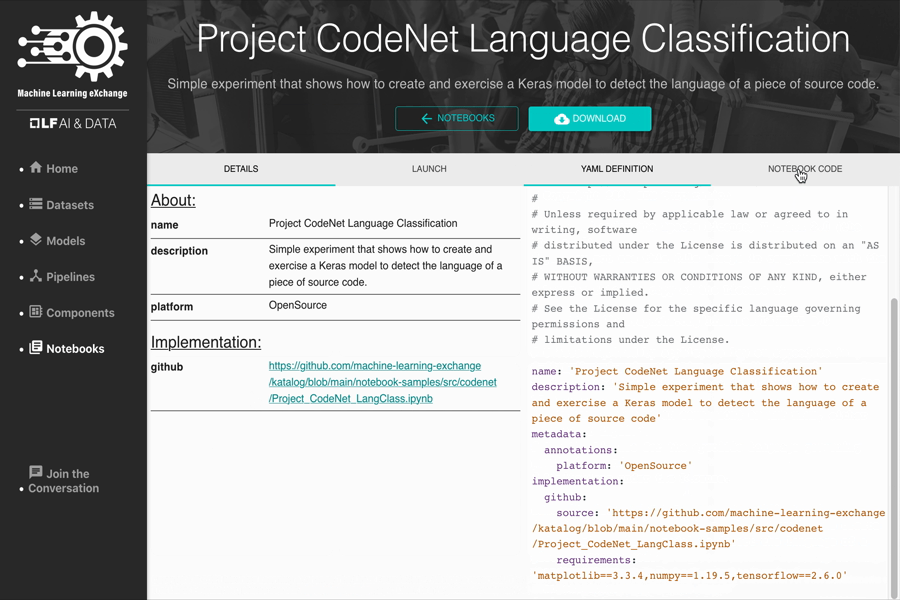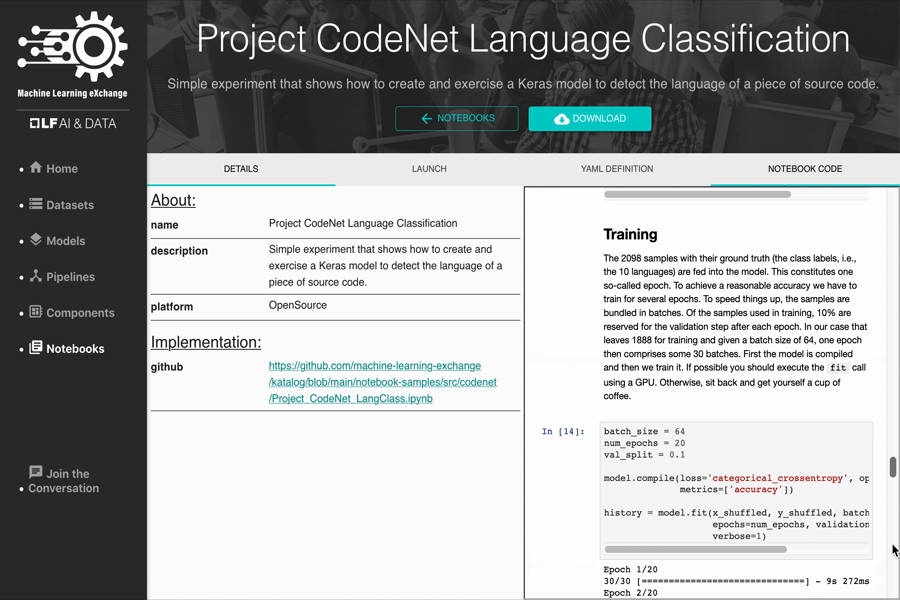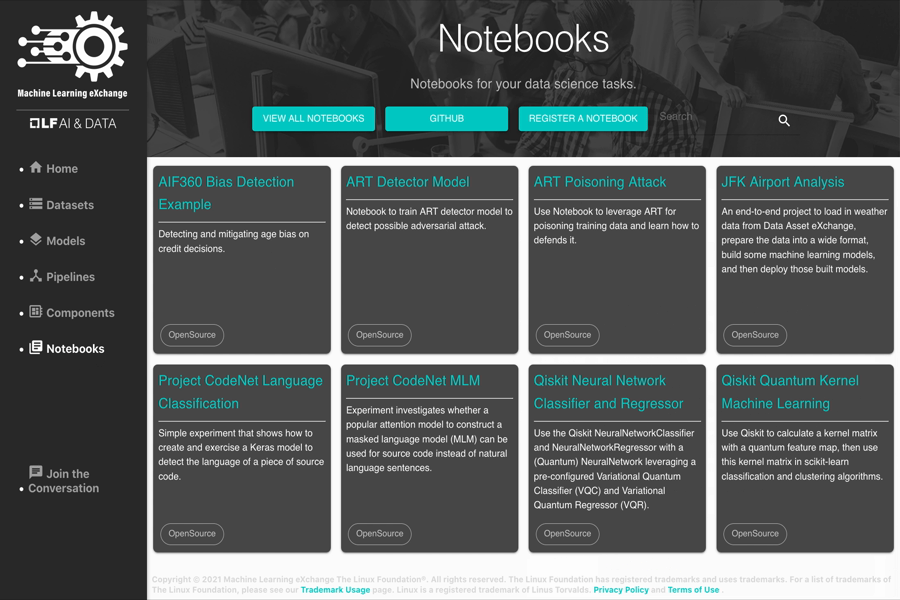
Join us to build cloud-native AI Marketplace on Kubernetes
The Machine Learning Exchange provides a marketplace and platform for data scientists to share, run, and collaborate on their assets. You now can use it to host and collaborate on Data and AI assets within your team and across teams. Please join us on the Machine Learning eXchange github repo, try it out, give feedback, and raise issues. Additionally, you can connect with us via the following:
- To contribute and build end to end Machine Learning Pipelines on OpenShift and Kubernetes, please join the Kubeflow Pipelines on Tekton project and reach out with any questions, comments, and feedback!
- To deploy Machine Learning Models in production, check out the KFServing project.
MLX Key Links
Thank You
Thanks to the many contributors of Machine Learning Exchange, mainly
- Andrew Butler
- Animesh Singh
- Christian Kadner
- Ibrahim Haddad
- Karthik Muthuraman
- Patrick Titzler
- Romeo Kienzler
- Saishruthi Swaminathan
- Srishti Pithadia
- Tommy Chaopling Li
- Yihong Wang
LF AI & Data Resources
- Learn about membership opportunities
- Explore the interactive landscape
- Check out our technical projects
- Join us at upcoming events
- Read the latest announcements on the blog
- Subscribe to the mailing lists
- Follow us on Twitter or LinkedIn
- Access other resources on LF AI & Data’s GitHub or Wiki